
Kubernetes autoscaling quickly gets tricky, but developers can save time and effort thanks to all the ecosystem’s tools that make configuration and management easier. One of them is Helm. Helm charts are there to help teams define, install, and upgrade complex Kubernetes applications. And the Cluster Autoscaler Helm Chart does some of the heavy lifting for you around autoscaling.
But how exactly does this Helm chart work? And are there any alternatives you could use to make cluster autoscaling even easier?
Let’s start with the basics: what is Cluster Autoscaler anyway?
Along with Kubernetes Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler, Cluster Autoscaler is one of the autoscaling mechanisms K8s provides.
Its goal is pretty simple: Cluster Autoscaler changes the number of nodes (worker machines) in a cluster.
Note that Cluster Autoscaler can only manage nodes on a handful of supported platforms. And every platform has its own specific requirements or limitations.
The tricky part here is that the autoscaler controller operates at the infrastructure level. To do its job, it needs permission to add and delete virtual machines (if you’re in the cloud).
So before you set Cluster Autoscaler to work, ensure airtight security for these credentials. Following the principle of least privilege is definitely a good idea (I’ll share some more Cluster Autoscaler best practices later on).
When should you use Cluster Autoscaler?
There’s no denying that a well-configured Cluster Autoscaler can make a massive impact on your cloud bill.
Three amazing things happen when you’re able to dynamically scale the number of nodes to match the current level of utilization:
- you minimize cloud waste,
- you maximize your ROI from every dollar you spend on cloud services,
- and, at the same time, you make sure there is no downtime as your application scales.
That isn’t to say that Cluster Autoscaler doesn’t have its limitations.
How does Cluster Autoscaler work?
Cluster Autoscaler simply loops through two tasks:
- It checks for unschedulable pods (pods that don’t have a node to run on),
- And it calculates whether consolidating all the currently deployed pods on a smaller number of nodes is possible or not.
Here’s how Cluster Autoscaler works, step by step:
Step 1: It scans clusters to identify any pods that can’t be scheduled on any existing nodes.
Where do unschedulable pods come from? The issue might arise because of inadequate CPU or memory resources or due to the pod’s node taint tolerations or affinity rules failing to match an existing node.
In addition to that, it could be that you have just scaled your application and the new pods haven’t found a node to run on yet.
Step 2: Cluster Autoscaler detects a cluster that contains unschedulable pods.
Next, it checks the managed node pools of this cluster to understand whether adding a node would let the pod run. If this is true, the autoscaler adds a node to the node pool.
Step 3: Cluster Autoscaler also scans nodes across the node pools it manages.
If it detects a node with pods that could be rescheduled to other nodes in the cluster, the autoscaler evicts the pods, moves them to an existing node, and finally removes the spare node.
Note: When deciding to move a pod, Cluster Autoscaler considers pod priority and PodDisruptionBudgets.
[DIAGRAM]
If you’re looking for more guidance on how to configure and run Cluster Autoscaler, here’s a hands-on guide to EKS Cluster Autoscaler with code snippets.
Why use the Cluster Autoscaler Helm Chart?
Let’s start with Helm. Helm is a package manager that has the sole purpose of making Kubernetes application deployment easier.
Helm does that via charts. There are two ways you can use it: you can create your own chart or reuse existing Helm charts. Once you start developing a lot of tools in your K8s cluster, you’ll be thankful for Helm charts.
But Helm doesn’t only help you with deployment. You can also manage releases, including rollbacks if something goes south in your deployment.
Let’s get back to the original topic of this article:
The Cluster Autoscaler Helm Chart is a configuration template that allows you to deploy and manage the Cluster Autoscaler component in Kubernetes using Helm (here’s the repo).
But Cluster Autoscaler comes with limitations
We’ve already started talking about maximizing utilization and minimizing cloud costs.
The problem with Cluster Autoscaler is that it doesn’t consider CPU or memory utilization in its decision-making process. All it does is check the pod’s limits and requests.
What does this mean in dollar terms? That the Autoscaler isn’t able to see all the unutilized capacity requested by pods. As a result, your cluster will end up being wasteful, and your utilization efficiency will be low.
Another issue with Cluster Autoscaler is that spinning up a new node takes more time than the autoscaler gives you, as it issues a request for scaling up within a minute. This delay might easily cause performance issues while your pods are waiting for capacity.
Finally, Cluster Autoscaler doesn’t take into account the changing costs of instance types, making the decisions less cost-optimized.
Is there an alternative to the Cluster Autoscaler Helm Chart?
The CAST AI autoscaler chooses the best matching instance types on its own or in line with your preferences, which can be easily configured.
The platform constantly monitors cloud provider inventory pricing and availability in supported cloud provider regions and zones. It uses these insights to pick instance families that deliver the most value.
Implementing the Cluster Autoscaler Helm Chart is easier than doing all the work on your own. But since CAST AI is a managed service, you really don’t need to spend a minute thinking about upgrades, scalability, and availability. And it comes with a Helm chart too!
Here’s an example that shows how closely the CAST AI autoscaler follows the real resource requests in the cluster.
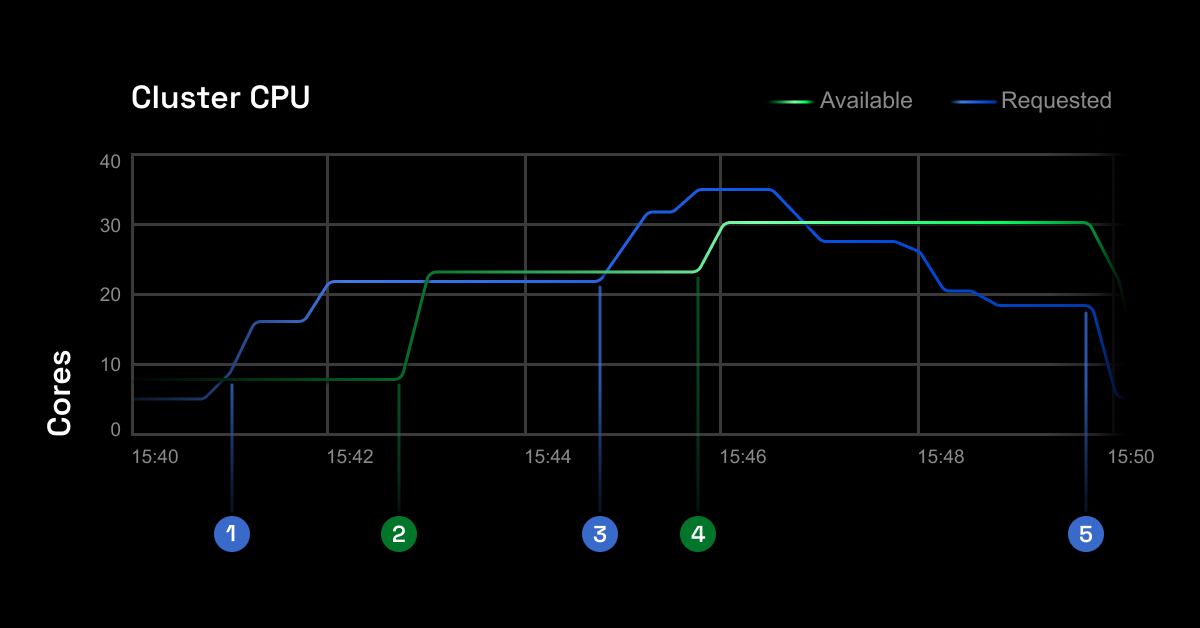
CAST AI works with Amazon EKS, Kops, and OpenShift, as well as GKE and AKS. If you’re looking for a reliable autoscaler that saves you money without causing any performance issues, dive into the documentation.
Or book a demo to get a personalized walkthrough of the platform.



