
As more organizations experiment with generative AI and LLMs, the diversity, compute availability, and costs of running the models are causing sticker shock and slowing adoption. Not all models are created equal, so knowing which model to use and where to run it are both essential for reducing costs.
The public release of ChatGPT in late 2022 catapulted Large Language Models (LLMs) and broader generative AI to the forefront of the global tech industry.
Teams around the world have built almost 30 thousand apps leveraging LLMs, with the majority running on OpenAI’s GPT models due to their high-quality outputs, steerability, and accessible API.
However, as more and more organizations started experimenting with generative AI and LLMs, they discovered how resource-consuming it is to run them as adoption increases. Not all large language models are created equal. Some may be more efficient than others in terms of cost, performance, and accuracy across numerous use cases.
What drives the cost of running LLMs? And what can teams do to reduce these expenses and run cost-efficient models?
This article dives into the details to help you understand how automation can reduce the cost of running LLM models at scale.
What are the key drivers of LLM costs?
When using LLMs, you’re likely to encounter two major price models:
- Paying by token – Your fee is based on the quantity of data handled by the model service. The costs are defined by the number of tokens (words or symbols) processed, both for inputs and outputs.
- Hosting your own model – In this scenario, you host LLMs on your own infrastructure, paying for the compute resources required to run them, particularly GPUs. You may also pay a license fee for the LLM.
While the pay-per-token business is simple and scalable, hosting your model gives you control over data protection and operational flexibility. However, it calls for a smart approach to optimizing cloud costs.
This is where automation can help.
4 automation tactics that reduce AI computing costs
Many teams use Kubernetes to containerize their applications, including AI models. There is only one caveat: Kubernetes scheduling guarantees that pods are assigned to the relevant nodes, but the process is all about availability and performance, with no regard for cost-effectiveness.
Kubernetes pods that run on half-empty nodes end up becoming very expensive, especially if we’re talking about GPU-intensive applications. Improper scheduling can easily lead to a huge cloud bill.
However, there are a few steps you can take to keep your cloud costs from increasing:
1. Autoscaling using node templates
To overcome this challenge, we created a system for provisioning and scaling low-cost GPU nodes for training.
CAST AI’s autoscaler and node templates automate the provisioning process, which engineers would normally have to carry out manually.
Workloads run on designated groups of instances. Instead of selecting particular instances manually, engineers may describe their features generally, such as “GPU VMs,” and the autoscaler will handle the rest. Given the current GPU shortages, expanding the number of computers available is a smart decision.
After the GPU operations are completed, the CAST AI autoscaler decommissions the GPU instances and replaces them with more cost-effective alternatives. All of this happens automatically, without anyone having to raise a finger.
2. Leveraging spot instances
Spot instances are the most cost-effective instance choice on Azure, AWS, and Google, with the potential to save you 90% off on-demand pricing. However, they may be interrupted at any time, with a notice of just 30 seconds to two minutes.
CAST AI has a mechanism in place to handle this by automating Spot instances throughout their lifecycle.
The platform determines the best pod configuration for your model’s computing needs and automatically picks virtual machines that fulfill workload parameters while selecting the most affordable instance families on the market.
If CAST AI cannot discover enough spot capacity to match a task’s requirements, it uses the Spot Fallback functionality to temporarily execute the job on on-demand instances until Spot instances become available. Once that is done, it effortlessly shifts workloads back to Spot instances, assuming users request this behavior.
3. Automating Inference
If your team uses their SDK or runtime, each cloud provider has excellent inference processors. CAST AI can generate node templates specifically for this sort of instance. Google (Tensor Streaming Processor), Azure, and AWS (Inf2) all have specific inference-based compute resources that come at much lower cost than GPUs or CPUs.
On Google Cloud Platform, the Tensor Streaming Processor (TSU) is specifically designed to optimize the operations commonly used in deep learning, including those involved in LLM inference.
TSUs excel in LLM inference due to their optimization for high-throughput matrix operations, ensuring speedy processing of extensive calculations. They’re energy-efficient, achieving more computations per watt than general-purpose processors, and their parallel processing capabilities allow for simultaneous handling of various model parts or data points, significantly enhancing inference speed.
AWS has launched Inf2, the latest version of Inferentia designed specifically for deep learning use cases. AWS Inferentia is a collection of purpose-built ML inference processors designed to provide high-performance, low-cost inference for a variety of applications.
These processors use a custom-built deep learning inference engine tuned for inference workloads to process DNNs extremely efficiently. This engine supports several prominent neural network topologies, including ResNet, VGG, and LSTM, among others.
Inferentia processors are available in various configurations, and they may be used with AWS services like Amazon SageMaker and AWS Deep Learning AMIs to develop and scale ML inference workloads.
4. Selecting the right LLM model
When picking the LLM for your project, you need to analyze the costs associated with specific users and API keys, overall usage patterns, the balance of input versus output tokens, and the potential costs of model fine-tuning.
We recently introduced a new LLM optimization service (called AI Optimizer) that does that automatically for specific categories:
Categories:
- Content Creation And Management
- Customer Service And Support
- Data Analysis And Insight Generation
- Workflow Automation And Efficiency
- Research And Development
- Training And Education
- Legal And Compliance
- Marketing And Sales
- Human Resources
- Strategic Planning And Decision Making
- Software Development And Engineering
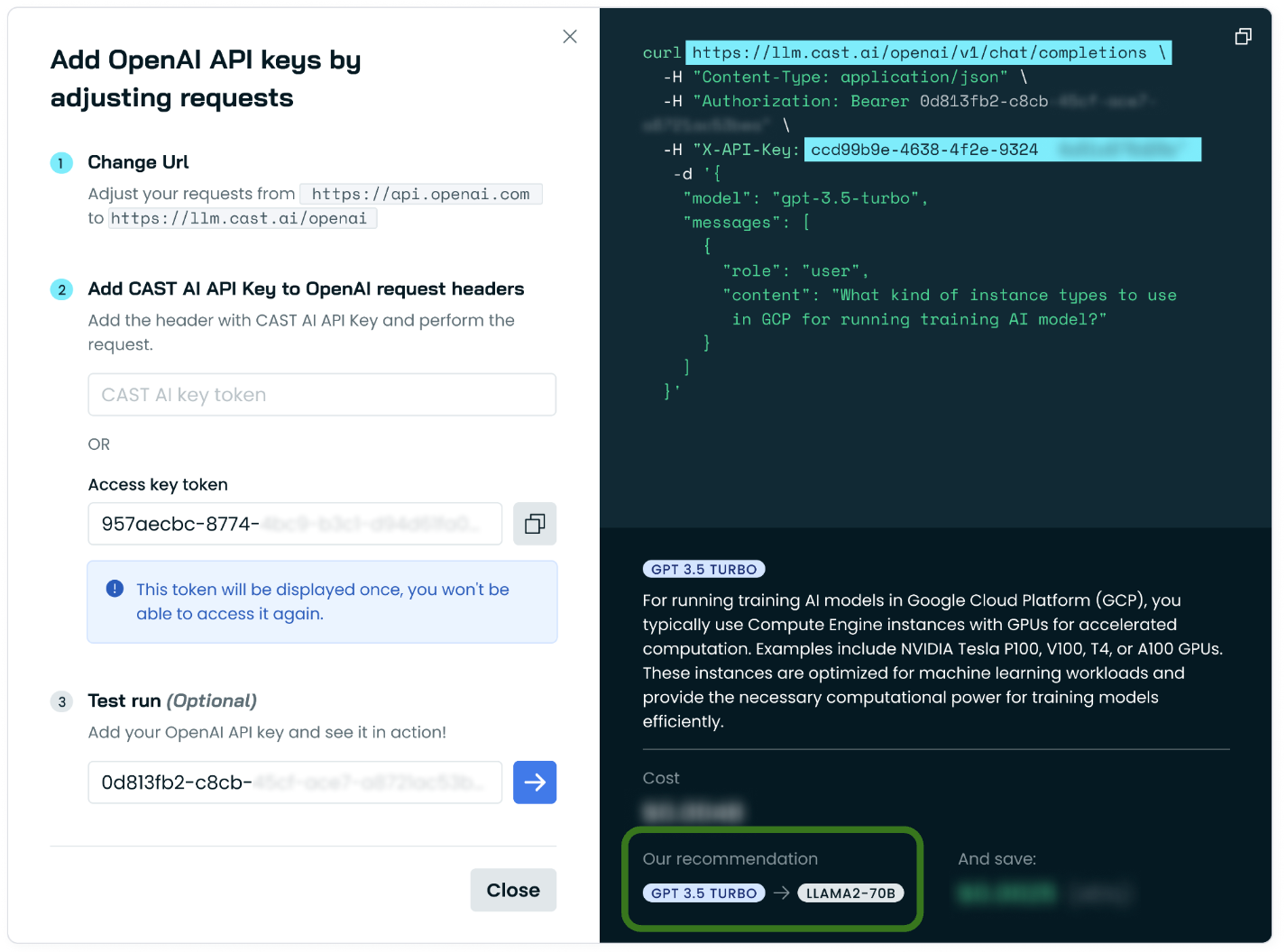
Our service integrates with any OpenAI-compatible API endpoint and automatically identifies the LLM across commercial vendors and open source that offers the most optimal performance and the lowest inference costs.
5. Deploying the model on ultra-optimized Kubernetes clusters
Our AI Optimizer then deploys the LLM on Kubernetes clusters that have been optimized using CAST AI automation features such as bin packing, autoscaling, and spot instance automation.
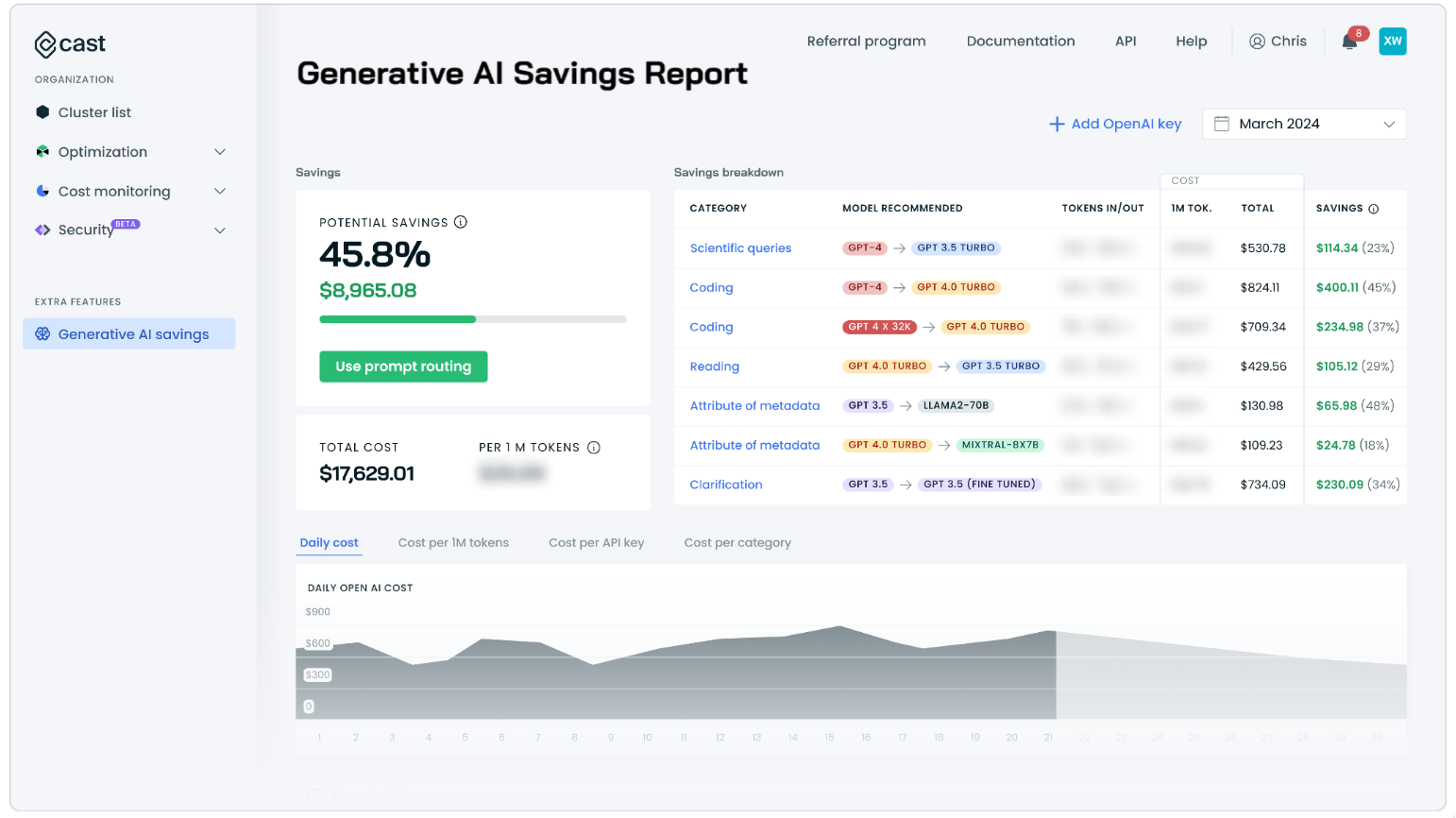
The service also comes with deep insights into model usage, fine-tuning costs, and explainability in optimization decisions – including model selection.
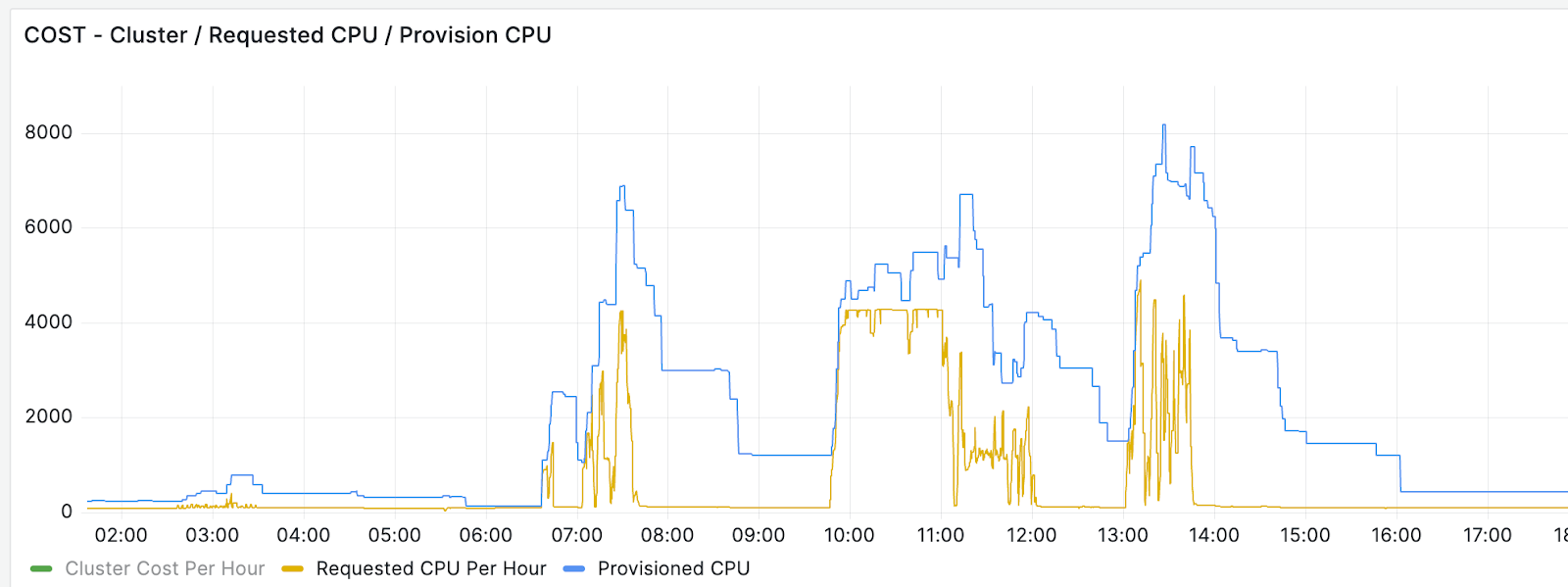
A non-optimized LLM workload on CPU/GPU:
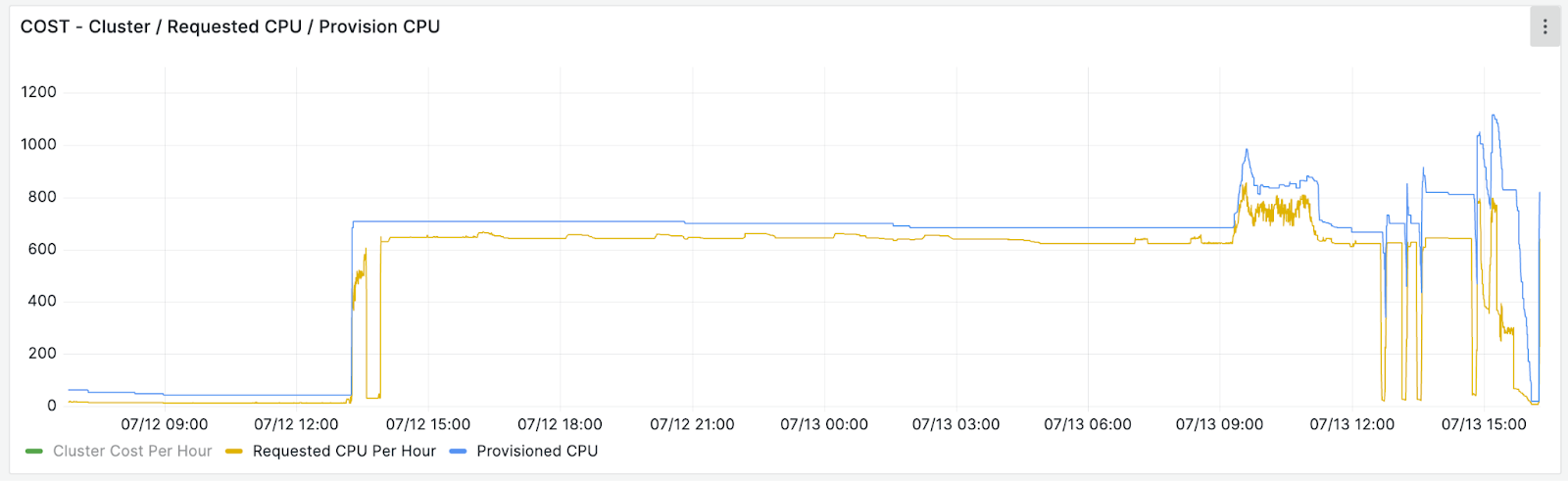
An optimized LLM workload (inference) on CPU/GPU on a CAST AI optimized cluster:
Follow this link to learn more.



