
We all love Kubernetes for its autoscaling capabilities and enjoy them when running clusters in a managed Kubernetes service like Amazon EKS. Many of you already have set up VPA and/or HPA for pod autoscaling to ensure that your application is scaled to meet the load demand. But at some point, you’re bound to face a new challenge – and this is where the EKS Cluster Autoscaler can help.
You might not get enough capacity in your cluster during peak times. Or you might experience the opposite – wasted hardware capacity during off-peak moments. The Cluster Autoscaler comes to the rescue!
In this guide, we will explore the EKS Cluster Autoscaler to show you how it works and share some best practices to help you always adjust capacity to demand.
When to use the Cluster Autoscaler?
The Cluster Autoscaler is one of the three Kubernetes autoscaling dimensions. It automatically adds or removes nodes in a cluster based on pod resource requests.
Contrary to Horizontal and Vertical Autoscalers, the Cluster Autoscaler doesn’t measure CPU and RAM usage values for its decisions. Instead, it checks the cluster every N seconds for pending pods in a “pending” state. That state indicates that the Kubernetes scheduler wasn’t able to assign these pods to a node because of insufficient cluster capacity or other conditions.
Teams use the Cluster Autoscaler to automate the process of scaling the number of nodes up or down in line with their application’s demand. The best part of using the Cluster Autoscaler is that it automatically does the scaling job for you.
That’s what makes the Cluster Autoscaler a great cost management tool. By using it, you can eliminate overprovisioning and cloud waste, paying only for as many cloud resources as your application really utilizes.
EKS Cluster Autoscaler: Autoscaling on AWS
Even managed Kubernetes usually doesn’t have built-in autoscaling out-of-the-box. For a long time, the official EKS documentation has recommended using the official Kubernetes Cluster Autoscaler.
Not a long time ago, Karpenter appeared on the scene. Karpenter is an open-source project that attempts to address some of the issues of the original Kubernetes Cluster Autoscaler.
Even though it faces new competition, the official Cluster Autoscaler remains a popular choice. Being vendor-neutral, widely adopted, and battle-tested, it’s an attractive option for many teams.
Setting the EKS Cluster Autoscaler up
Usually, the Cluster Autoscaler is installed as a Kubernetes Deployment in the cluster, in the kube-system namespace. You can set up the Autoscaler to run several replicas and use the leader election mechanism for high availability.
However, note that actually only one replica is responsible for scaling at a time (the elected leader). It’s important to understand that multiple replicas won’t provide horizontal scalability. This means that you need to adjust it vertically to be able to handle your cluster load.
The Cluster Autoscaler is a core component of the Kubernetes control plane. It’s there to help you make decisions around scaling and scheduling.
Where does Amazon EKS come in? It might be confusing to differentiate between the official Kubernetes Cluster Autoscaler and EKS Cluster Autoscaler.
When you’re running your cluster in an AWS-managed service, the cloud provider offers an extension that makes it all work. This extension of the Kubernetes Cluster Autoscaler communicates its decisions to the AWS infrastructure using APIs (for example, to manage the EC2 instances where your cluster is running).
Before I show you how to set up the EKS Cluster Autoscaler, let’s review how it works.
Glossary
Before diving into the how, let’s define some terms used in this guide and official documentation:
- Cluster Autoscaler – a piece of software that automatically performs cluster scale-up or scale-down when needed. It adds or removes nodes in your cluster.
- Official Kubernetes Cluster Autoscaler – this cluster autoscaler is provided by the Kubernetes community (SIG Autoscaling).
- EKS Cluster Autoscaler – EKS cluster autoscaler is an extension that bridges the Official Kubernetes Cluster Autoscaler to integrate with AWS infrastructure. Check out this GitHub page to learn more about the Cluster Autoscaler on AWS.
- Node Group – Node groups are groups of nodes within a cluster. They’re not actual resources, but you can find them as an abstraction in the Cluster Autoscaler, Cluster API, and other Kubernetes components. When grouped, nodes may share several common properties like labels and taints but still run on a different instance type or in a different Availability Zone.
- EKS Auto Scaling Group – Auto Scaling groups is an AWS EC2 feature to scale the number of instances up or down. We could say that it is an implementation of Node groups in EKS.
How does EKS Cluster Autoscaler work?
What the Cluster Autoscaler does is looping through two tasks: checking the cluster for unschedulable pods and calculating whether it’s possible to consolidate all the currently deployed pods on a smaller number of nodes.
Here’s how the Cluster Autoscaler works step by step:
- It scans the cluster to detect any pods that can’t be scheduled on any existing nodes. This might result from inadequate CPU or memory resources, and another common reason is that pod’s node taint tolerations, or affinity rules don’t match any existing nodes.
- Suppose the Cluster Autoscaler finds a cluster that has some unschedulable pods. It then checks its managed node pools to understand whether adding a node would unblock the pod or have no effect at all. The Autoscaler adds one node to the node pool if it’s the former.
- It also scans nodes in the node pools it manages, and if it identifies a node on which pods could be rescheduled to other nodes in the cluster, it evicts them and removes the spare node. When deciding to move a pod, the Cluster Autoscaler considers factors around pod priority and PodDisruptionBudgets.
Since the Autoscaler controller works on the infrastructure level, it needs permissions to view and manage node groups. That’s why security best practices like the principle of least privilege are key here – you must do your best to securely manage these necessary credentials.
A hands-on guide to EKS Cluster Autoscaler
Here is a quick lab so that you can see the EKS Cluster Autoscaler in action. We will use the most straightforward way to set it up, starting with the cluster itself. We will use the eksctl command to make things easier.
There are a few prerequisites before Cluster Autoscaler can be installed:
- A working environment with aws, eksctl and kubectl command line tools,
- EKS cluster,
- OIDC provider,
- Auto Scaling Group with Tags,
- IAM Policy And Service Account.
Only the first one is mandatory to be prepared before starting. Other prerequisites can be created by following provided steps.
1. Create the cluster
If you don’t have an EKS cluster running or want to experiment on a temporary cluster, let’s create it.
Note: If you create a cluster following this guide, don’t forget to delete it to stop expenses (the command is provided in the last step).
> eksctl create cluster --name ca-demo-cluster --instance-types=t3.medium --nodegroup-name ng-t3m --nodes 2 --nodes-max=4 --spot --asg-access --vpc-nat-mode DisableThis will create a cluster called ca-demo-cluster, with an Auto Scaling node group “ng-t3m” including two nodes initially and a max capacity of four nodes. The spot nodes parameter is specified to create cheaper instances. We also specify –asg-access to prepare it for autoscaling.
Note: In some regions, some instance types or spot instances might not be available. Try using another instance type if the creation fails due to instance capacity errors.
2. Set up the OIDC provider
If you are setting up autoscaler in an existing cluster, then please check out the documentation to check if you already have an OIDC provider.
If you’ve just created a new cluster, you can enable the OIDC provider like this:
> eksctl utils associate-iam-oidc-provider --cluster ca-demo-cluster --approve3. Auto Scaling Groups and Tags
If you used the eksctl command in the previous step to create your node groups, these tags should already be there. For an existing cluster, you should check and add if they do not exist.
Required tags (adjust the cluster name in the second tag):
k8s.io/cluster-autoscaler/enabled = true
k8s.io/cluster-autoscaler/ca-demo-cluster = owned4. IAM Policy
Store this content to file policy.json. Note: adjust the cluster name if you used a different one.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"aws:ResourceTag/k8s.io/cluster-autoscaler/ca-demo-cluster": "owned"
}
}
},
{
"Effect": "Allow",
"Action": [
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeAutoScalingGroups",
"ec2:DescribeLaunchTemplateVersions",
"autoscaling:DescribeTags",
"autoscaling:DescribeLaunchConfigurations"
],
"Resource": "*"
}
]
}Now run this command to create an IAM policy. You can adjust the policy name or file name.
> aws iam create-policy \
--policy-name DemoClusterAutoscalerPolicy \
--policy-document file://policy.jsonTake note of the created policy ARN in the command output. You’ll need to specify it in the next step.
In case you missed it, you can check it again using this:
> aws iam list-policies --query 'Policies[*].[PolicyName, Arn]' --output text | grep DemoClusterAutoscalerPolicy5. IAM Service Account
Now let’s create a Service account and attach our newly created policy. Make sure to set the correct ARN from the previous step:
> eksctl create iamserviceaccount \
--cluster=ca-demo-cluster \
--namespace=kube-system \
--name=cluster-autoscaler \
--attach-policy-arn=arn:aws:iam::1111111111:policy/DemoClusterAutoscalerPolicy \
--override-existing-serviceaccounts \
--approve6. Deploy the Cluster Autoscaler
We already have all the prerequisites and are ready to deploy the Autoscaler itself.
Download the Kubernetes deployment file:
> curl -o cluster-autoscaler-autodiscover.yaml https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yamlWe need to make a few small adjustments in the file:
Replace <YOUR CLUSTER NAME> with the correct name of the cluster (ca-demo-cluster if you created it by following the previous steps).
Verify and adjust the container image version to the corresponding version compatible with the Kubernetes version in your cluster (version compatibility).
I recommend adding the command line argument –skip-nodes-with-system-pods=false to the container command for more flexible scaling down.
Now, let’s deploy it to our cluster:
> kubectl apply -f cluster-autoscaler-autodiscover.yamlYou should be able to see the cluster-autoscaler deployment and pod in the kube-system namespace.
> kubectl get deploy/cluster-autoscaler -n kube-system
> kubectl get pods -n kube-system -l=app=cluster-autoscalerIn pod logs, you should see messages about cluster state and scaling decisions (replace with the correct pod name in the command).
> kubectl logs cluster-autoscaler-POD-NAME -n kube-systemIf there are any errors related to authorization – possibly any of the steps related to OIDC or IAM Policy and Service Account were not completed correctly.
7. Testing cluster autoscaling
Let’s create a simple deployment to trigger cluster scale-up.
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-app
spec:
selector:
matchLabels:
app: test-app
replicas: 1
template:
metadata:
labels:
app: test-app
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
resources:
requests:
cpu: 1000m
memory: 1000Mi> kubectl apply -f test-app.yamlThis should create The deployment “test-app” with a single pod. Now, let’s scale it to have more replicas:
> kubectl scale --replicas=6 -f test-app.yamlCheck the pod status:
> kubectl get pods -l=app=test-appInitially, some pods should be pending. Then autoscaling should be triggered, and more nodes should be added to the cluster. Some pods could be left unscheduled (pending) if the Auto Scaling group reaches the max number of nodes. Try adjusting the replica count to your needs.
Now let’s reduce the replica count to see the Cluster Autoscaler downscaling action:
> kubectl scale --replicas=0 -f test-app.yamlThe number of nodes will go down after a few minutes. You can recheck the Autoscaler pod logs to see which decisions were made.
8. Destroy the created resources
Clusters and VMs incur costs in your cloud provider account. If you created a cluster by following the steps in this guide, destroy it as soon as you’re done playing around using this command:
> eksctl delete cluster --name ca-demo-cluster6 best practices for EKS Cluster Autoscaler
Set the least privileged access to the IAM role
If you use Auto Discovery, it’s smart to use the least privilege access by limiting the Actions autoscaling:SetDesiredCapacity and autoscaling:TerminateInstanceInAutoScalingGroup to the Auto Scaling Groups scoped to the current cluster.
Why is this important? This is how you prevent the Cluster Autoscaler from running in one cluster by modifying node groups in a different cluster. Even if you didn’t scope the –node-group-auto-discovery argument down to the node groups of the cluster using tags (for example, k8s.io/cluster-autoscaler/<cluster-name>).
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"autoscaling:ResourceTag/k8s.io/cluster-autoscaler/enabled": "true",
"aws:ResourceTag/k8s.io/cluster-autoscaler/<my-cluster>": "owned"
}
}
},
{
"Effect": "Allow",
"Action": [
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeAutoScalingGroups",
"ec2:DescribeLaunchTemplateVersions",
"autoscaling:DescribeTags",
"autoscaling:DescribeLaunchConfigurations"
],
"Resource": "*"
}
]
}Configure node groups well
To make your autoscaling effort worth the time, start by configuring a set of node groups for your cluster. If you pick the right set of node groups, you’ll maximize availability and reduce cloud costs across all of your workloads.
In AWS, node groups are implemented with EC2 Auto Scaling Groups that offer flexibility to a broad range of use cases. Still, the Cluster Autoscaler needs to make some assumptions about your node groups, so it pays to keep the configuration consistent with them.
For example, each node needs to have identical scheduling properties (labels, taints, resources). Instead of creating many node groups containing fewer nodes, try creating fewer nodes with many nodes. This will have the greatest impact on scalability.
Use the correct Kubernetes version
Kubernetes is evolving fast, and its control plane API changes often. The maintainers of Cluster Autoscaler do not guarantee compatibility with other versions than that for which it was released. When deploying the EKS Cluster Autoscaler, ensure you use a matching version. You can find a compatibility list here.
Check node group instances for the same capacity
If you don’t, the Cluster Autoscaler won’t work as expected. Why? Because it assumes that every instance in your node group has the same amount of CPU and memory. The Cluster Autoscaler takes the first instance type in the node group for scheduling simulation.
If your group contains instance types with more resources, they won’t be utilized – this means wasted resources and higher costs. And vice versa, if there is an instance type with fewer resources – pods won’t fit to be scheduled on it.
That’s why you must double-check that the node group that will undergo autoscaling contains instances or nodes of the same type. And if you’re managing mixed instance types, ensure they have the same resource footprint.
Define resource requests for each pod
The Cluster Autoscaler makes scaling decisions based on pods’ scheduling status, as well as individual node utilization. If you fail to specify resource requests for every pod, the autoscaler won’t work as it should.
When scaling up, Cluster Autoscaler chooses instance types according to pod resources.
When scaling down, it will look for nodes with utilization lower than the specified threshold. To calculate utilization, it sums up the requested resources and compares them to node capacity.
If there are any pods or containers without resource requests, Autoscaler’s decisions will definitely be affected, and you’ll be facing an issue.
Make your life easier and double-check that all the pods scheduled to run in an autoscaled node or instance group have their resource requests specified.
Set the PodDisruptionBudget wisely
PodDisruptionBudget (PDB) helps in two ways. Its main mission is to prevent your applications from disruption. PDB will protect from evicting all or a significant amount of pods of a single Deployment or StatefulSet. The Cluster Autoscaler will respect PDB rules and downscale nodes safely by moving only the allowed number of pods.
On the other hand, PDB can help to downscale not only in a restrictive way but also in a permissive one. By default, the Cluster Autoscaler won’t evict any kube-system pods unless PDB is specified. So, by specifying a reasonable PDB, you will enable the Cluster Autoscaler to evict even kube-system pods and remove underutilized nodes.
Note: Before an eviction, the Cluster Autoscaler ensures that evicted pods will be scheduled on a different node with enough free capacity.
When specifying the PodDisruptionBudget, consider the minimum necessary number of replicas of the pods. Many system pods run as single instance pods (aside from Kube-dns), and restarting them might cause disruptions. So, don’t add a disruption budget for single instance pods like metrics-server; you’ll sleep better at night.
Curious to see a modern autoscaler in action?
By constantly monitoring cloud provider inventory pricing and availability in supported cloud provider regions and zones, we have collected data and knowledge on which instance families provide the best value and which should be avoided. That’s how CAST AI Cluster Autoscaler can select the best matching instance types on its own (or according to your preferences).
Given that it’s a managed service, you don’t need to worry about upgrades, scalability, and availability. CAST AI platform is monitoring clusters and is always ready to act promptly.
Here’s an example showing how closely the CAST AI autoscaler follows the actual resource requests in the cluster.
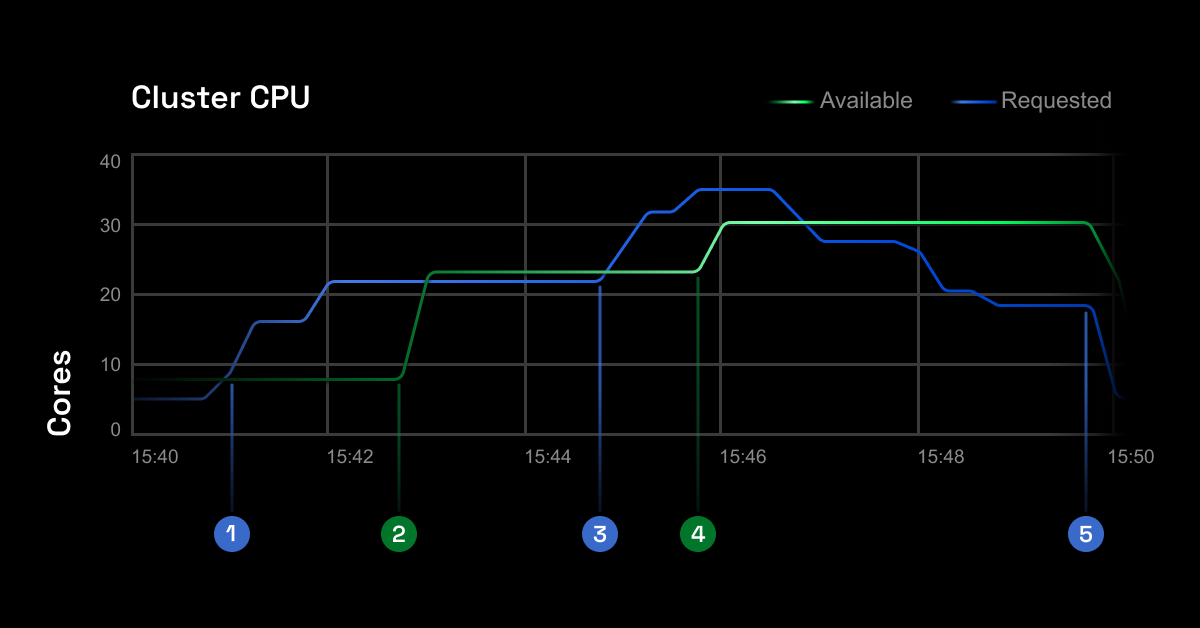
Check how well your cluster is doing in terms of autoscaling and cost-efficiency. Check out instance recommendations by connecting your cluster to our free and read-only mode Kubernetes cost monitoring module – it works with Amazon EKS and Kops, as well as GKE and AKS.
CAST AI clients save an average of 63% on their Kubernetes bills
Connect your cluster and see your costs in 5 min, no credit card required.



