As teams adopt Kubernetes, low resource utilization becomes a plague. The State of Kubernetes Overpovisioning report found that 37% of CPUs for cloud-native applications are never used, on average.1 CAST AI automates Kubernetes deployment and frees these resources to be used more efficiently.

What exactly does the CAST AI platform automate – and how? Keep reading to find out the five areas of running Kubernetes that call for automation and see how our platform solves the challenge.
1. Compute instance selection and rightsizing
Why is it challenging?
Picking the right machine for the job is challenging for many reasons. When choosing virtual machines for workloads, teams should order only what they need across multiple compute dimensions, including CPU (and type x86 vs. ARM, or vs. GPU), Memory, SSD, and network connectivity.
Taking the time to check all the available options is worth it because compute is often one of the largest cost items on a cloud account.
But how can engineers make the right choice manually when the major cloud providers provide them with hundreds of machine types and sizes? Going through the list of 400+ AWS instances every single time you want to provision a node just isn’t realistic.
How CAST AI helps you automate it
CAST AI automatically selects, provisions, and decommissions compute instances in line with dynamically changing workload demands.
The platform:
- Analyzes the workload to understand its CPU and RAM requirements,
- Looks through the hundreds of options from AWS, Google Cloud, and Microsoft Azure,
- Finds the best performance match at the lowest possible cost,
- Provisions the resource automatically so the workload has a place to run.
Dive into the details in our documentation.
Real-life example
The leading provider of automation and AI solutions for clinical and regulatory matters, Phlexglobal, used this CAST AI feature and saved 60% on its cloud expenses.
We may have a memory-intense workload or CPU-intensive workload and need the right cloud resources to run them. Doing that natively within Kubernetes is a lot more difficult. You need to create separate node pools, set up the tolerations, and follow up on that process.
With CAST AI, it’s pretty much just an annotation, and then the solution will act on its own, buying more resources in line with our requirements. This makes the lives of our engineers easier.
Alex Potter-Dixon, VP Cloud Engineering and Operations at Phlexglobal
Read the full case study here.
2. Autoscaling
Why is it challenging?
Kubernetes comes with three autoscaling mechanisms you can use to increase resource utilization and reduce cloud waste. The tighter these scaling mechanisms are configured, the lower the waste and costs of running your application.
However, configuration and management of Horizontal Pod Autoscaler, Vertical pod Autoscaler, and Cluster Autoscaler are time-consuming and challenging, especially if teams use more than one autoscaler.
There are open-source solutions on the market that provision and optimize nodes automatically, removing them when no longer needed. However, they also require time-consuming configuration and constant supervision to make everything run smoothly.
How CAST AI automates it
The CAST AI autoscaler scales cloud capacity up and down to match real-time demand changes without causing downtime. It’s simple to set up and runs automatically in line with the policies you set for it.
For example, you can use Node Templates to define virtual buckets of constraints such as:
- instance types to be used,
- lifecycle of the nodes to add,
- node provisioning configurations,
- and other properties.
CAST AI will respect all the above settings when creating nodes for your workloads to run on. Learn more in the documentation.
Here’s how closely the CAST AI autoscaler follows the actual resource requests in the cluster:
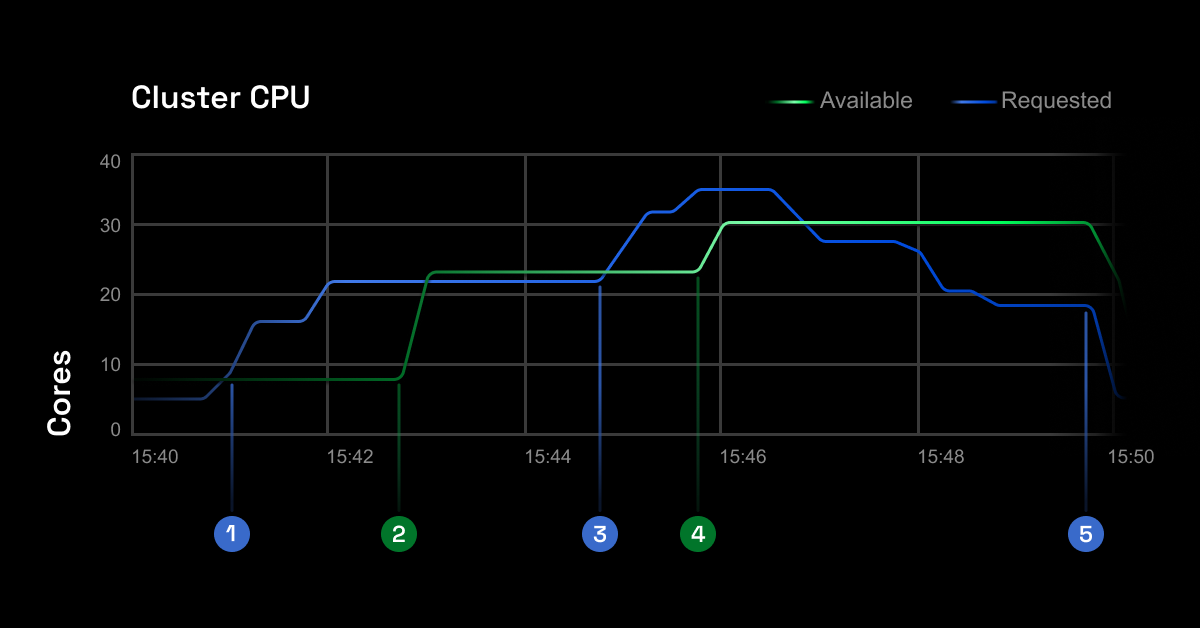
Real-life example
The IT consultancy Wohlig Transformations uses the CAST AI autoscaler to reduce the workload of engineers, who no longer need to manage the infrastructure manually.
The UI is very understandable and user-friendly, helping DevOps to easily implement policies – like the node deletion policy that automatically removes nodes from the cluster when they no longer have scheduled workloads to keep a minimal footprint and reduce costs.
We were working with a client and onboarded CAST AI for them. The company had a few dev servers that were quite heavy. They wanted to shut down the entire server outside of working hours and during weekends.
Implementing this without CAST AI would take our developers a lot of time. They would have to write scripts and manage it all manually. With CAST AI, we could complete this task in a single day.
Chintan Shah, Founder and CTO at Wohlig
Read the full case study here.
3. Downscaling
Why is it challenging?
The Kubernetes scheduler distributes pods across nodes with fairness in mind, not maximum node utilization or cost efficiency. But to reduce your cloud bill, you need to bin pack pods to nodes and instantly remove empty nodes to avoid paying for idle resources. Kubernetes makes that hard to do manually because things happen so quickly.
CAST AI includes an automated solution that continuously compacts pods into fewer nodes, creating empty nodes that can be removed following the Node deletion policy (if you enable it). To avoid any downtime, Evictor will only consider applications with multiple replicas.
How CAST AI automates it
Evictor removes only empty nodes that haven’t been used for a certain period of time to save costs and reduce waste. Nodes may be empty because all the pods running on them have been deleted due to reasons like ReplicaSet scaling down or Job completion.
To manage downscaling, CAST AI users have two solutions at their disposal:
- Node deletion policy – it removes nodes that are empty and no longer running in any capacity. For example, if a job you’re running goes past its run time, a node may become empty. CAST AI will automatically remove it to avoid cloud waste. Learn more here.
- Evictor – it identifies pods running on underutilized nodes and checks whether they could be scheduled somewhere else in your cluster. When such a combination of nodes and pods is found, it cordons the node, drains it, and moves workloads to another node, lowering cloud waste and removing empty nodes in line with the Node deletion policy. Learn more about Evictor here.
Real-life example
In this practical case study, we reduced the costs of running Kubernetes on Amazon EKS by 66% using CAST AI in 15 minutes.
We started by provisioning an e-commerce app (here) on an EKS cluster with six m5 nodes (2 vCPU, 8 GiB) on AWS EKS. Next, we deployed CAST AI to analyze the application and suggest optimizations. Finally, we activated automated optimization and watched nodes get bin-packed for greater utilization and lower cloud waste.
The initial cluster cost was $414 per month. Within 15 minutes, in a fully automated way, the cluster cost dropped to $207 (a 50% reduction) – this was thanks to reducing six nodes to three nodes.
Then, 5 minutes later, the cluster cost went down to $138 per month because we turned spot instance automation on (noting a 66% reduction).

Read the full step-by-step guide here.
4. Instantly moving workloads to optimal compute instances
Why is it challenging?
While cloud cost optimization takes time, sometimes teams may want to immediately move their workloads to different machines once they discover potential savings via recommendations. Spinning up new compute instances and moving pods to them takes time and effort, impacting the potential ROI from optimization activities.
How CAST AI automates it
CAST AI doesn’t only show which compute instances offer the best price-performance ratio for a given Kubernetes deployment. The platform also allows users to instantly replace some (or all) of the non-optimized nodes with the most cost-efficient ones available via a feature called rebalancing.
Real-life example
Let’s return to the practical case study we presented in the previous step.
CAST AI gradually shrank the cluster by bin-packing pods and emptying nodes one by one. From that moment on, the cluster is optimized, and Evictor will continuously look for further optimization opportunities over time.
The next step is running full rebalancing, where the platform assesses all the nodes in the cluster and then replaces some (or all of them) with the most cost-efficient nodes available that meet my workload requirements.
The nodes are first cordoned off:

The first two nodes are drained, and the platform selects the most appropriate instance type for these nodes. This is what you’ll see in the CAST AI dashboard:
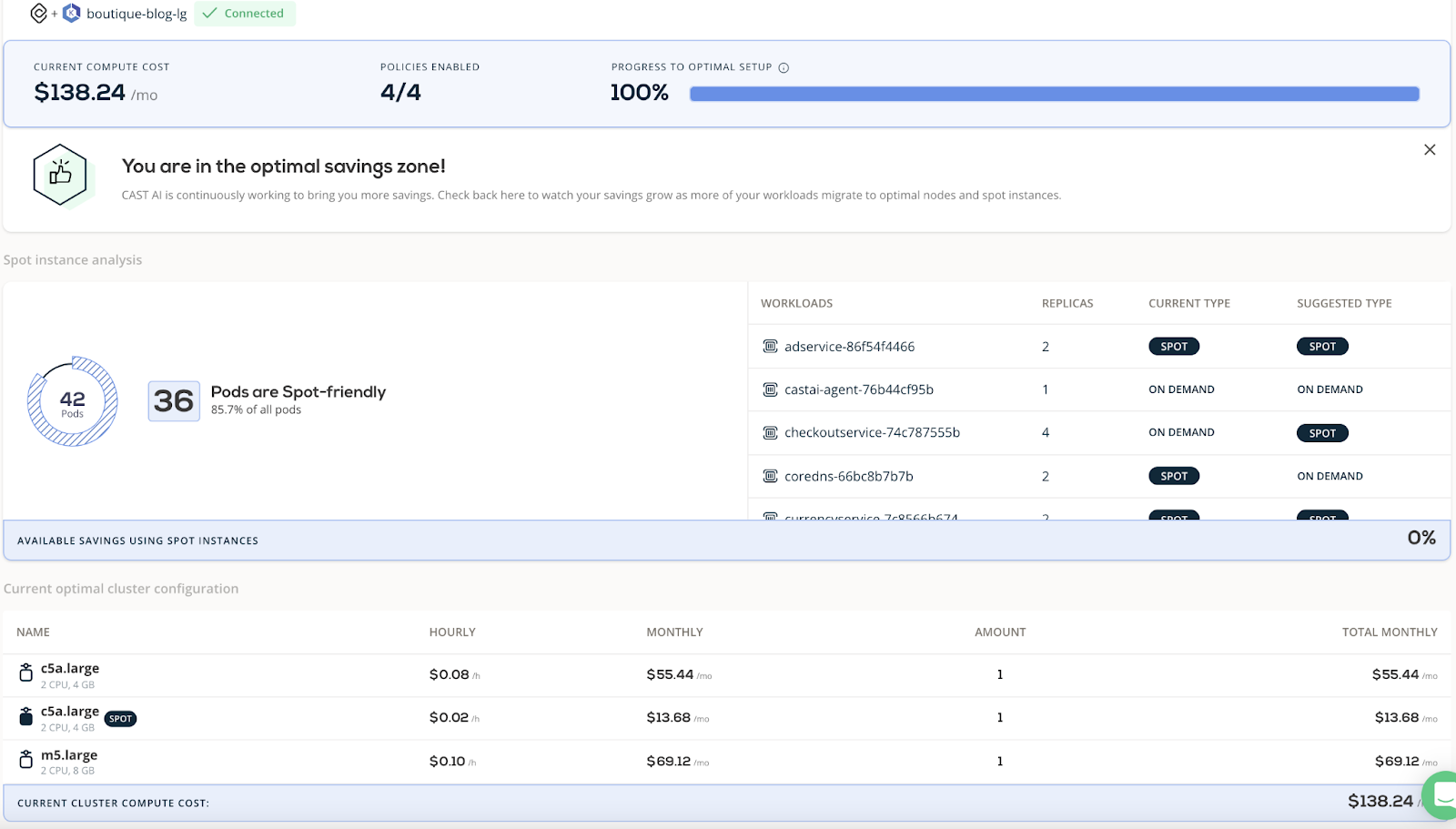
The cluster now has only two nodes and costs $138 per month. It’s hard to imagine that we started this case study with a monthly EKS bill of $414.72!
Read the full step-by-step guide here.
5. Spot instance automation
Why is it challenging?
Spot instances (also called spot VMs) offer an incredible cost-saving opportunity. However, they come with a caveat. The cloud provider may reclaim them with as little as 30 seconds’ notice. Spinning up a new instance takes more than that, so your workload will be left without a place to run, which could potentially make your application go down.
This is just the tip of the iceberg when it comes to spot instances:
- Since you get these instances via a bidding process, you’re the one to specify the price per hour. The spot instance will serve you only if nobody else outbids you.
- Spot instances shut down instantly after their pricing goes beyond your maximum bid.
- The provider might run out of spot instances to offer, which often happens during busy seasons like the Christmas holidays. On such occasions, our customer OpenX encountered limits in the network, compute, and storage capacities.
How CAST AI automates it
CAST AI automates the entire spot instance lifecycle to help teams take advantage of these cost-efficient resources. The platform finds the best match for a given workload, provisions the instance, and, if an interruption occurs, relocates workloads to a new spot instance or an on-demand instance in case of lack of availability.
Decommissioning
Once there are no more jobs to be done, CAST AI shuts instances down automatically. You don’t want to spend money on resources that don’t bring your business any value, even when they’re as cost-efficient as spot instances.
Spot fallback mechanism
When a shortage of spot instances happens, CAST AI moves workloads to on-demand instances to minimize the risk of interruption and make sure that all workloads have a place to run.
Partial utilization of spot instances
CAST AI gives users the flexibility to run just a portion of workloads on spot instances without having to modify manifest files. All they need to do is install and configure a Mutating Admission Webhook (mutating webhook), which mutates the workload manifest and adds spot toleration to influence the desired pod placement by the Kubernetes Scheduler.
If set to spot-only, the webhook will mark all workloads in the cluster as suitable for spot instances. As a result, the platform’s autoscaling mechanism will prefer spot instances when scaling your cluster up.
This is especially important for development and staging environments, batch job processing clusters, and other circumstances where interruptions will not create problems. If running 100% of your workloads on spot instances seems daunting, you can easily change it to run 60% on steady on-demand instances and 40% on spot instances.
Spot instance automation works together with all the previous mechanisms described, making the package a huge value added over automating these aspects separately.
Learn more about this feature here or in the documentation.
Real-life example
The programmatic advertising platform OpenX runs nearly 100% of its compute on spot instances and uses automation and the spot fallback feature to ensure workloads always have a place to run by moving them to on-demand resources in case of a spot drought.
We certainly have spot fallback always enabled, and it’s a normal situation for us to be unable to obtain spot capacity at the moment. But the capacity situation at Google Cloud is very dynamic.
If you can’t obtain the spot capacity now, you might be able to in 10 minutes. That’s why spot fallback works great for us – we can expect CAST AI to maintain the best possible cost for the cluster by constantly attempting to replace the on-demand capacity with spot.
Ivan Gusev, Principal Cloud Architect at OpenX
Read the full case study here.
Automate Kubernetes deployment with CAST AI
We built CAST AI to help Kubernetes teams run their clusters without worrying about the most tedious aspects of managing the underlying infrastructure – and save a serious buck in the process. Our customers save 60%+ on average, check out their stories.
CAST AI provides a suite of automation solutions in one place, with all of them working together to deliver benefits. Implementing the platform is a fast process, and the timeline to ROI is short, contrary to the open-source solutions available for some of the automation areas mentioned above.
CAST AI barely requires any oversight while being used, enabling engineers to solve business-critical problems instead of working on the infrastructure.
Book a demo to get a personalized walkthrough of our platform and learn more about its automation features.
CAST AI clients save an average of 63%
on their Kubernetes bills
Book a call to see if you too can get low & predictable cloud bills.





Leave a reply