
MLflow has become the go-to platform for teams looking to track ML projects throughout their lifecycle. The three major cloud providers have responded to this demand by offering a growing toolkit for developing AI applications. However, building and running AI models in the cloud quickly becomes very costly.
If you use MLflow with cloud-based AI models, there are some ways to make your cloud bill lower.
7 best practices for reducing your ML cloud bill
1. Choose the right infrastructure for running your ML project
If you’re still planning your ML project, this is the best time to compare different cloud providers and their pricing models for compute and managed AI services (AWS SageMaker, Google Cloud Vertex AI, and Azure ML Studio).
Choose machines from specific instance families
Most teams that play around with ML prefer to use GPU-dense machines due to their superiority in such applications compared to CPUs. This includes a much larger parallelism and acceleration of model training and inference. For our deep learning-based models, we saw up to an 8x speedup when switching to GPUs from CPUs.
Let’s make a quick comparison of GPU-powered virtual machine offerings across AWS, Azure, and Google Cloud:
AWS
- P3 – good match for ML and HCP applications, the instances in this family have up to 8 NVIDIA V100 Tensor Core GPUs and up to 100 Gbps of networking throughput. According to AWS, P3 reduces ML training times to minutes and increases the number of simulations completed for HPC by 3-4x.
- P4d – powered by NVIDIA A100 Tensor Core GPUs, these instances deliver the highest performance combined with high throughput and low latency networking.
- G3 – these GPU graphics instances provide a combination of CPU, host memory, and GPU capacity for graphics-intensive applications.
- G4 – using NVIDIA T4 Tensor Core GPUs, instances in this family give you access to one or multiple GPUs, with various volumes of vCPU and memory. Great for deploying ML models in production. This group includes G4dn and G4ad instances,
- G5 – this family provides high performance GPU-based instances for ML inference.
Note: AWS also offers Inferentia machines equipped with specialized chips that provide great performance for deep learning libraries.
Google Cloud Platform
- A2 – these accelerator-optimized machines are powered by NVIDIA A100 GPUs, with each including a fixed GPU count, vCPU count, and memory size.
- G2 – this accelerator-optimized family includes instances with a fixed number of NVIDIA L4 GPUs and vCPUs attached, with default memory and a custom memory range.
- N1 – machines in this family run on NVIDIA T4 or P4 GPUs, and ones with lower numbers of GPUs have limits around the maximum number of vCPUs.
Google Cloud Platform provides a handy comparison chart to help you understand which GPUs are the best match for your needs.
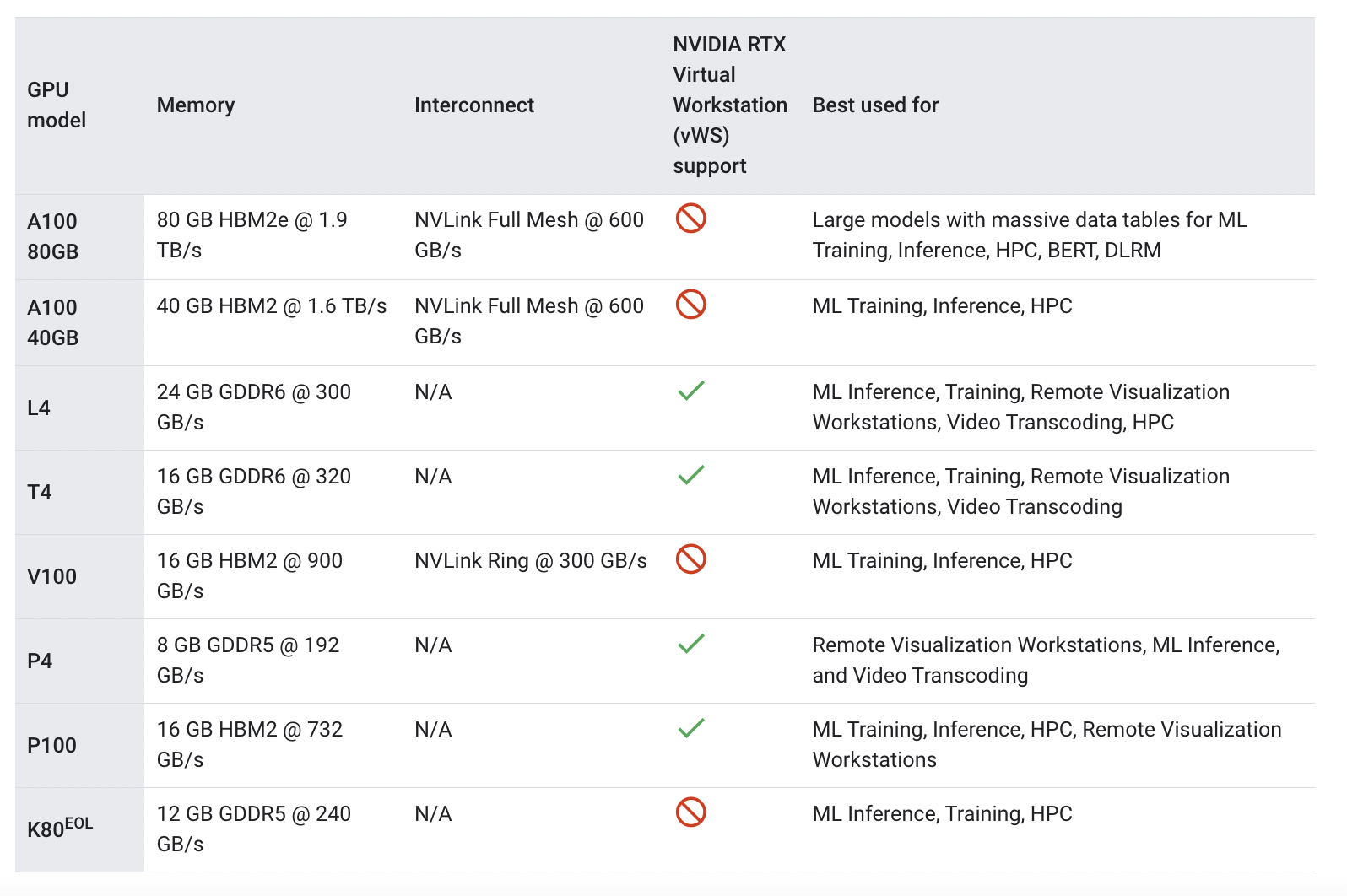
Source: GCP
Azure
- NCv3-series – this family is concentrated on high-performance computing and AI workloads, powered by NVIDIA’s Tesla V100 GPU.
- NC T4_v3-series – this machine is powered by NVIDIA’s Tesla T4 GPU and AMD EPYC2 Rome processor, focused on inference.
- ND A100 v4-series – these machines come in handy for scale-up and scale-out deep learning training and accelerated HPC applications. They use 8 NVIDIA A100 TensorCore GPUs, with a 200 Gigabit Mellanox InfiniBand HDR connection and 40 GB of GPU memory.
- NV-series and NVv3-series – optimized and designed for remote visualization, streaming, gaming, encoding, backed by the NVIDIA Tesla M60 GPU.
- NDm A100 v4-series – this machine type was designed for high-end deep learning training and tightly coupled scale-up and scale-out HPC workloads. The family starts with a single VM and eight NVIDIA Ampere A100 80GB Tensor Core GPUs.
Pick the right instance for the job
Analyze your workload requirements and the needs of the specific AI models across all compute dimensions including CPU (and type x86 vs ARM), Memory, SSD, and network connectivity.
Since we’re talking about ML here, you’re likely assessing GPU-dense instances, given they’re so much faster than CPU.
Remember that cloud providers are constantly launching new instance types for inference, such as Amazon EC2 Inf2, powered by AWS Inferentia2, the second-generation AWS Inferentia accelerator. According to AWS, Inf2 raises the performance of Inf1 with 3x higher compute performance, 4x larger total accelerator memory, and up to 4x higher throughput.
Use spot instances for non-critical tasks
Take advantage of the incredible savings post instances/preemptible VMs offer for non-critical tasks that are interruption-tolerant, like model development or experimentation. Running batch jobs at an 80-90% discount just makes sense.
However, you still need to prepare for the provider to reclaim the instance at any time, giving you only a 2-minute (AWS) or 30-second (GCP, Azure) warning. Luckily, solutions using spot interruption prediction models allow you to predict upcoming reclaims and move compute to other instances before interruption happens.
Automating instance provisioning is the right solution for this scenario – you don’t want to experience downtime even if you’re running an ML experiment.
Use GPU time slicing
In the context of Kubernetes, GPU time slicing lets pods share a single GPU. Multiple apps can operate on one GPU since each receives a piece of its processing power, leading to massive cost savings. This is an upcoming feature in CAST AI.
2. Optimize resource utilization
Overprovisioning is a common issue in the cloud, no matter if you’re working on ML or running an e-commerce application.
Luckily, there are a few things you can do here to use the resources you pay for smarter:
- Use containerization and orchestration tools to scale resources – tools like CAST AI will help you scale resources up and down in line with the demand from AI workloads.
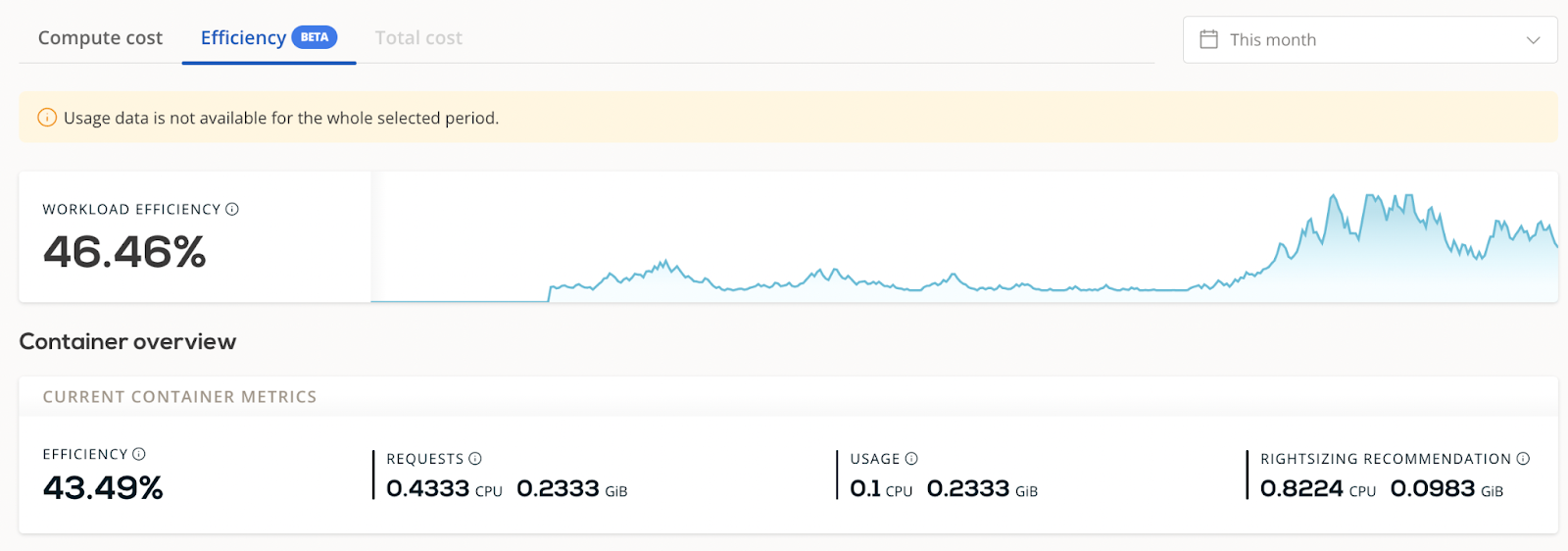
- Monitor resource consumption using tools like Grafana and third-party monitoring solutions – if you run models on Kubernetes, CAST AI gives you access to real-time ML lifecycle job consumption data for full transparency. You can see workload efficiency metrics that instantly tell you whether your workload is really using the capacity you set for it.
- Implement resource pooling and sharing – this opens the door to more efficient resource allocation, particularly for AI tasks.
3. Optimize data storage and transfer
Another smart move is looking at your data storage and transfer fees. If you move data from one AZ to another, you might end up paying a pretty high egress fee on every move.
How do you reduce the costs of AI model training? Here are a few tips.
Compress data
Do it before storing or transferring it. The Parquet file format is very useful when training more traditional ML models that use tabular data. By switching from CSV to Parquet, you can save ~10x of storage and gain quite a few performance benefits thanks to the columnar Parquet format.
Cache intermediate results
This is how you can minimize data transfer fees and expedite AI model inference. Vector databases are a key innovation here. They have entirely changed how we use exponential amounts of unstructured data in object storage. This method is use-case specific but works really well for LLM-based applications.
For tabular data-based models good data compression is the key as flat blob storage is slow and expensive to maintain. Utilizing k8 persistent volumes is a great alternative offering low latency.
Implement data lifecycle policies
This opens the door to automatically managing storage costs, which is a particular gain for large AI models. A good example of this is a data retention policy specifying when a team can remove data and if not, where the data will be stored after a specified amount of time (for example, moved to cold storage).
4. Implement efficient machine learning pipelines
As an MLflow user, you probably realize its potential for building efficient ML pipelines. But here are a few tips for ever more efficiency:
- Use MLflow Projects for reusability and modularity, streamlining AI model development.
- Optimize hyperparameter tuning for improved AI model performance. A recent release of MLflow has introduced a chart view that allows you to identify the most optimal hyperparameter values.
- Take advantage of distributed training for faster training of large-scale AI models (think deep learning models).
- Employ MLflow Model Registry to manage and share AI models efficiently. Model registry and experiment run metadata capabilities allow you to link only performant models to the desired stage from where your model can be used for model inference.
5. Monitor and optimize costs for AI model deployments
Cost management is a key part of building any AI model. After all, you can’t have its ROI clouded by the sheer amount of dollars it took to get the project off the ground.
Set up cost monitoring and alerting
You can use native cloud provider tools or third-party solutions. CAST AI’s free cost monitoring module is a great example of this, especially since you get access to costs in real time – and things can quickly get out of hand in the cloud world.
Regularly review and optimize your ML deployments
It’s good to keep tabs on how your deployments are going from a cost perspective. When doing that, focus on AI model management in particular – this is where you’ll see the greatest impact.
Implement cost-saving policies and guidelines within your organization
To control cloud costs, you need all hands on deck. Spreading awareness of how much resources cost among engineers is the greatest challenge to the entire FinOps project, not only trying to ship efficient AI models.
One of our lead engineers shared practices that have worked well for us here: Control Cloud Costs and Build a FinOps Culture with Grafana
Continuously evaluate new things
Cost is one of the prohibitive factors for startups that prevents them from experimenting with AI. However, the AI market is flourishing and new tools are popping up all over the place.
The same goes for cost-saving features and techniques related to cloud-based AI models. Raising money isn’t easy and finance teams are looking for ways to cut expenses.
6. Use managed services and serverless architectures
There are so many solutions on the market that can make your life easier. Why not delegate the groundwork, so have the energy to tackle new challenges?
You can use serverless architectures for event-driven and on-demand AI workloads. Also, evaluate serverless data processing options for preprocessing the data for your AI models and potentially feature engineering.
7. Invest in training and skill development
This might sound obvious, but the world of AI is changing at an increasing pace, and even the most seasoned engineers might find keeping up with the cost-efficiency novelties and working full-time challenging.
That’s why it pays to provide training to team members on cost-effective management of both MLflow and AI model deployments. Be sure to share your knowledge and best practices with the entire organization.
To stay updated on the latest cost-saving techniques for cloud-based AI models, make sure to attend webinars, workshops, and conferences on the topic like Strata Data & AI or KDD.
Wrap up
Following these best practices is like taking a few large steps towards the end goal: running MLflow cost-effectively, especially when it comes to cloud-based AI models.
And don’t think that these steps are all one-off jobs. Optimization is a continuous effort. You need to regularly evaluate and refine your cost-saving strategies for MLflow when handling cloud-based AI models.
That’s why automation can help a bunch here. It lifts infra management tasks off your shoulders so you can focus on the fun part. Read this case study to see how it works in a real-life scenario:



