
Training AI models has never been buzzier – and more challenging due to the current GPU shortage. Whether it’s broken supply chains or the sudden AI explosion, one thing is clear: getting a GPU-powered virtual machine is hard, even if you’re fishing in the relatively big pond of the top three cloud providers. So, what can you do when you’re facing a quota issue and can’t get enough GPUs for your project?
GPU shortage is a fact
According to one analysis, the situation is pretty simple: there is “a huge supply shortage of Nvidia GPUs and networking equipment from Broadcom and Nvidia due to a massive spike in demand.”
Access to compute is currently one of the largest obstacles to AI development – even for OpenAI, which is seeing its progress stalled by the lack of GPUs.
The present scarcity is only going to become more painful as inference workloads increase along with wider AI adoption. Training is another story. Using machines with CPUs isn’t going to cut it in the world of machine learning. At CAST AI, we saw up to an 8x speedup when switching from CPUs to GPUs for our deep learning-based models.
How to deal with the GPU shortage? 3 potential solutions
If you’re checking your cloud provider’s GPU inventory repeatedly and can’t find the machines you need, here are a few potential solutions:
1. Buy hardware on your own
This seems like an easy way out. If AWS or Microsoft can’t give you what you need, you might start looking elsewhere – specifically, into your own backyard.
But this approach is expensive. We’re not only talking about all the money you’ll need to pour upfront for your new hardware. There’s also the effort and time invested in building and managing your own hardware infrastructure.
Also, you have no guarantees that GPUs will be available from Nvidia or its resellers. Everyone is after H100 and the like.
2. Get GPUs from multiple cloud providers
This is an interesting solution. You’re already in the cloud, so why not create a few other accounts with AWS, Azure, and Google to get your hands on GPU VMs?
You already know how hard managing a single cloud provider is. Doing the same for three providers at the same time might cause more headaches than benefits. And those benefits aren’t a given either since all providers experience shortages.
Note about GPUs prices across AWS, Azure, and Google Cloud
GPU prices vary across cloud providers. To show this, let’s take an example.
We will compare offerings available from AWS, Azure, and Google Cloud for virtual machines equipped with 4 Nvidia V100 GPUs that have 64 GB of GPU memory.
Here are the closest instance types we’re going to compare:
| Provider | Instance type | GPUs | vCPUs | Memory (GiB) | Memory (GPU) |
| AWS | p3.8xlarge | 4 | 32 | 244 | 64 |
| Azure | Standard_NC24s_v3 | 4 | 24 | 448 | 64 |
| Google Cloud | n2-standard-32 | 4 | 32 | 128 | 64 |
And here’s the pricing comparison (per hour) – as you can see, some providers offer much larger discounts for spot instances:
| Provider | Instance type | On-demand | Spot |
| AWS | p3.8xlarge | $12.24 | $3.672 |
| Azure | Standard_NC24s_v3 | $12.24 | $6.19 |
| Google Cloud | n1-standard-64 | $11.67 | $3.418 |
Note: The set OS is Linux and the region is US East (N. Virginia) – save for Google Cloud, where the region is US-East1 (South Carolina).
3. Use cloud automation to enlarge your GPU supply
Alternatively, you can stay with your cloud provider and have a good look around to see if you somehow missed machine families that happen to be equipped with GPUs.
Just to give you a full picture, the three major cloud providers offer a number of instance families with GPUs:
AWS
- P3
- P4d
- G3
- G4 (this group includes G4dn and G4ad instances)
- G5
Note: AWS also offers Inferentia machines with TPUs that offer great performance for specific deep learning libraries.
Google Cloud Platform
- A2
- G2
- N1
Azure
- NCv3-series
- NC T4_v3-series
- ND A100 v4-series
- NDm A100 v4-series
Choosing instances manually can easily lead you to miss out on opportunities for snatching up the golden GPUs from the market. That’s why teams are starting to use cloud automation solutions to find a much larger supply of GPU VMs at a controlled cost.
One of our customers – a company building an AI-driven security intelligence platform – encountered this problem. They solved it by using our platform’s node templates, an autoscaling feature that improves the provisioning and performance of workloads that require GPU-enabled instances.
How cloud automation beats GPU shortage
Our customer was working on an AI-powered intelligence solution for detecting dangers in social and news media in real time. Its engine examines millions of texts at the same time to detect developing storylines and lets users create unique Natural Language Processing (NLP) models for intelligence and defense.
The product uses an increasing volume of classified and public data. As a result, its workloads frequently require GPU-enabled instances.
To be more efficient, teams working in the public cloud create node pools (Auto Scaling groups). But while node pools accelerate the process of provisioning new instances, they can also be very expensive, causing you to pay for capacity that doesn’t get used.
CAST AI’s autoscaler and node templates build on this by providing cost management and reduction features. Node templates also open the door to using more cost-efficient machine types, such as spot instances.
The node template form looks as follows:
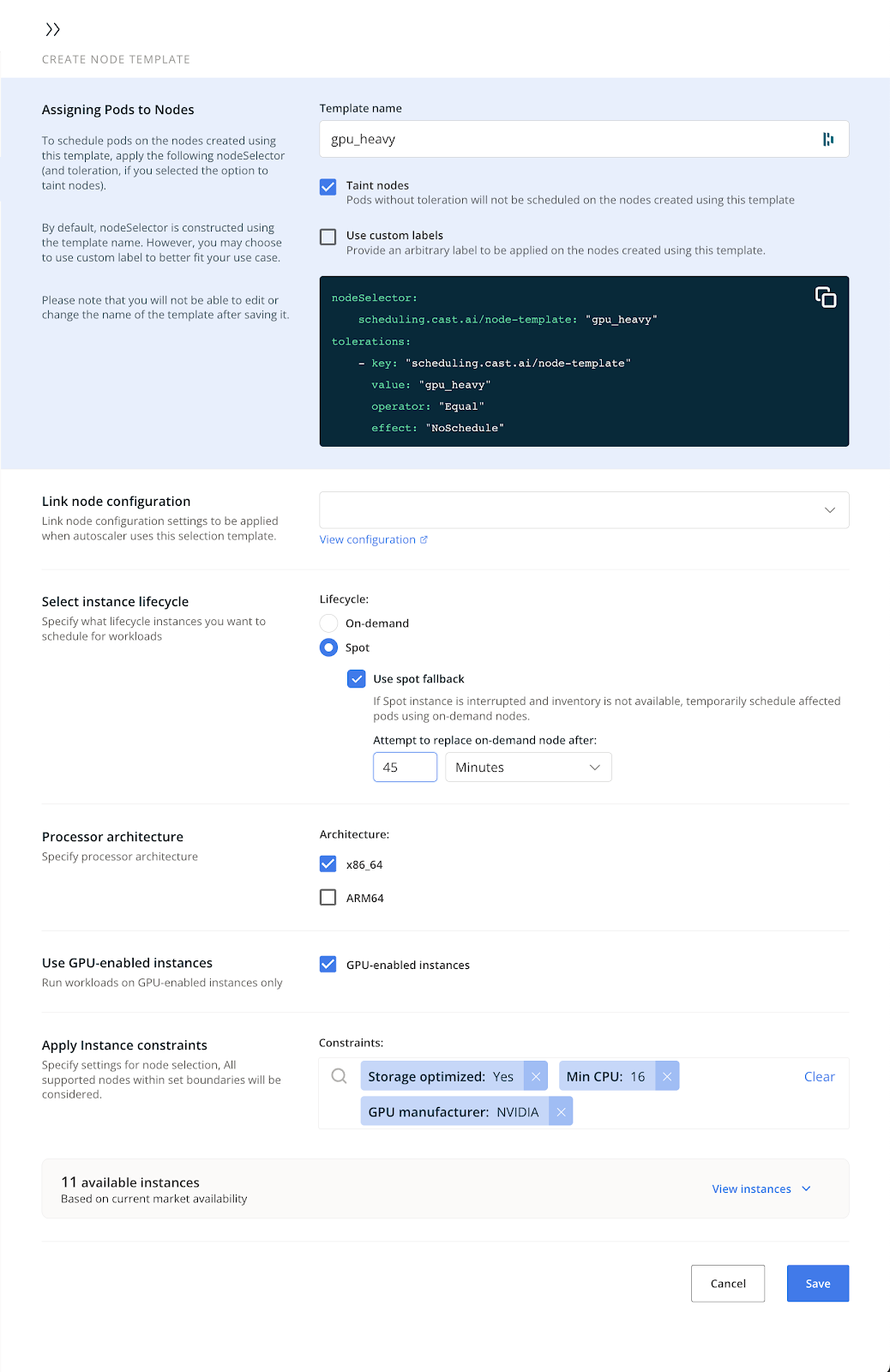
Instead of manually selecting instances, your team can broaden their features, such as “CPU-optimized,” “Memory-optimized,” and “GPU VMs,” and the autoscaler will do the rest. This allowed our customer to choose from a wider selection of instances.
As AWS introduces new, high-performance instance families, CAST AI automatically enrolls applications for them, so that’s another task that gets removed from the engineer’s to-do list. With node pools, you would still need to monitor new instance types and change your configuration accordingly.
Our customer can describe the requirements, such as instance kinds, the lifespan of the new nodes to be added, and provisioning configurations when setting up a node template. In the example above, they defined limits such as the example families they didn’t want to use (p4d, p3d, and p2) and the GPU manufacturer (in this case, Nvidia).
CAST AI discovered five machines that matched these specific parameters. When adding additional ones, the autoscaler will adhere to these limitations.
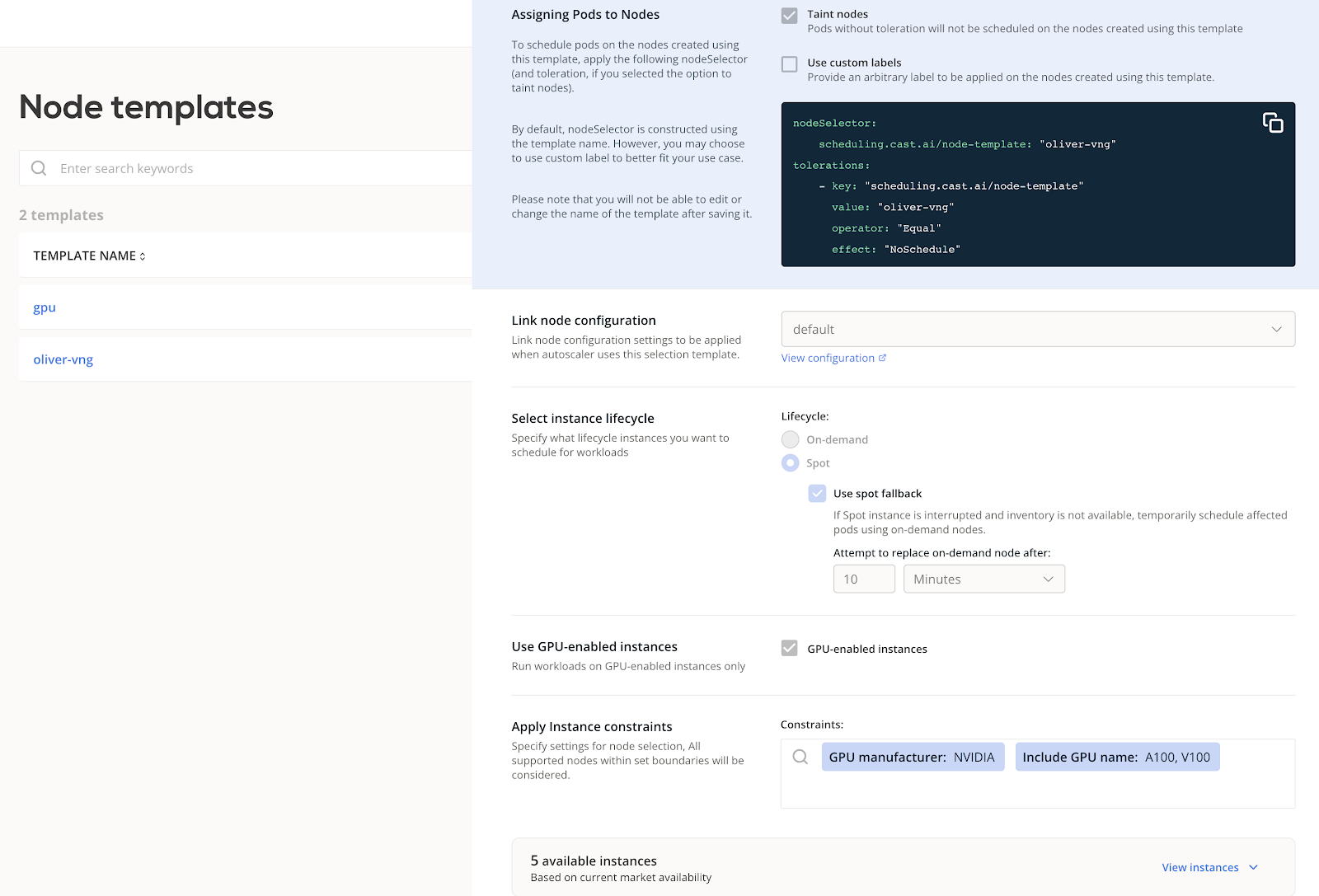
When the GPU task is completed, the autoscaler immediately decommissions GPU-enabled instances to help the team minimize the cost of running it.
Go for GPU spot instances to cut training and inference costs
With spot instance automation, teams stand to save up to 90% on large GPU VM expenditures while avoiding the all the issues caused by interruptions. Since GPU spot costs can change substantially, it’s critical to select the most optimal ones at the time. The spot instance automation of CAST AI is in charge of this.
What happens when GPU spot instances aren’t available anymore? If you’re running a deep learning job, an interrupted and improperly preserved training process might result in significant data loss.
But if AWS withdraws all EC2 G3 or p4d spaces that your workloads have been using all at once, the automatic fallback feature will save you the trouble. Your workload will keep running on on-demand capacity until the right spot instances become available again.
___
Interested to see how the platform’s AI-focused features play out in real life? Book a demo to get a personalized walkthrough of the CAST AI platform.
CAST AI clients save an average of 63%
on their Kubernetes bills
Book a demo and snatch the GPU machines you need.



