
Autoscaling is one of the biggest challenges facing teams that run Kubernetes clusters on Azure Kubernetes Service (AKS).
Engineers have to adjust cloud resources to their workload demands in real-time yet they have so many other tasks crying for their attention. This is where the automated autoscaler comes to the rescue.
As described by Alex Potter-Dixon, Head of DevOps at PhlexGlobal, “where the technology is truly transformative is in its ability to optimize our cluster and keep it optimized over time. As a matter of fact, CAST AI continuously configures our cluster over time, always finding the optimal balance of high performance at the lowest possible cost.”
How can AKS users benefit from the Advanced Autoscaler?
Autoscaling is one of the most effective optimization methods for Kubernetes. The tighter your Kubernetes scaling mechanisms are configured, the lower the waste and costs of running the application.
CAST AI provides a mix of automation mechanisms to make standard autoscaling on EKS, Kops, AKS, and GKE clusters even more efficient:
- Real-time autoscaling – the platform uses business metrics to come up with the optimal number of required pod instances. It then scales the replica count of pods up and down as needed, scaling to zero and removing all pods if there’s no more work to be done. The mechanism ensures that the number of nodes in use matches the application’s requirements at all times.
- Headroom policy – when a pod suddenly requests more CPU or memory than the volume of resources you have available on any of the worker nodes, the autoscaler matches the demand by keeping a buffer of spare capacity.
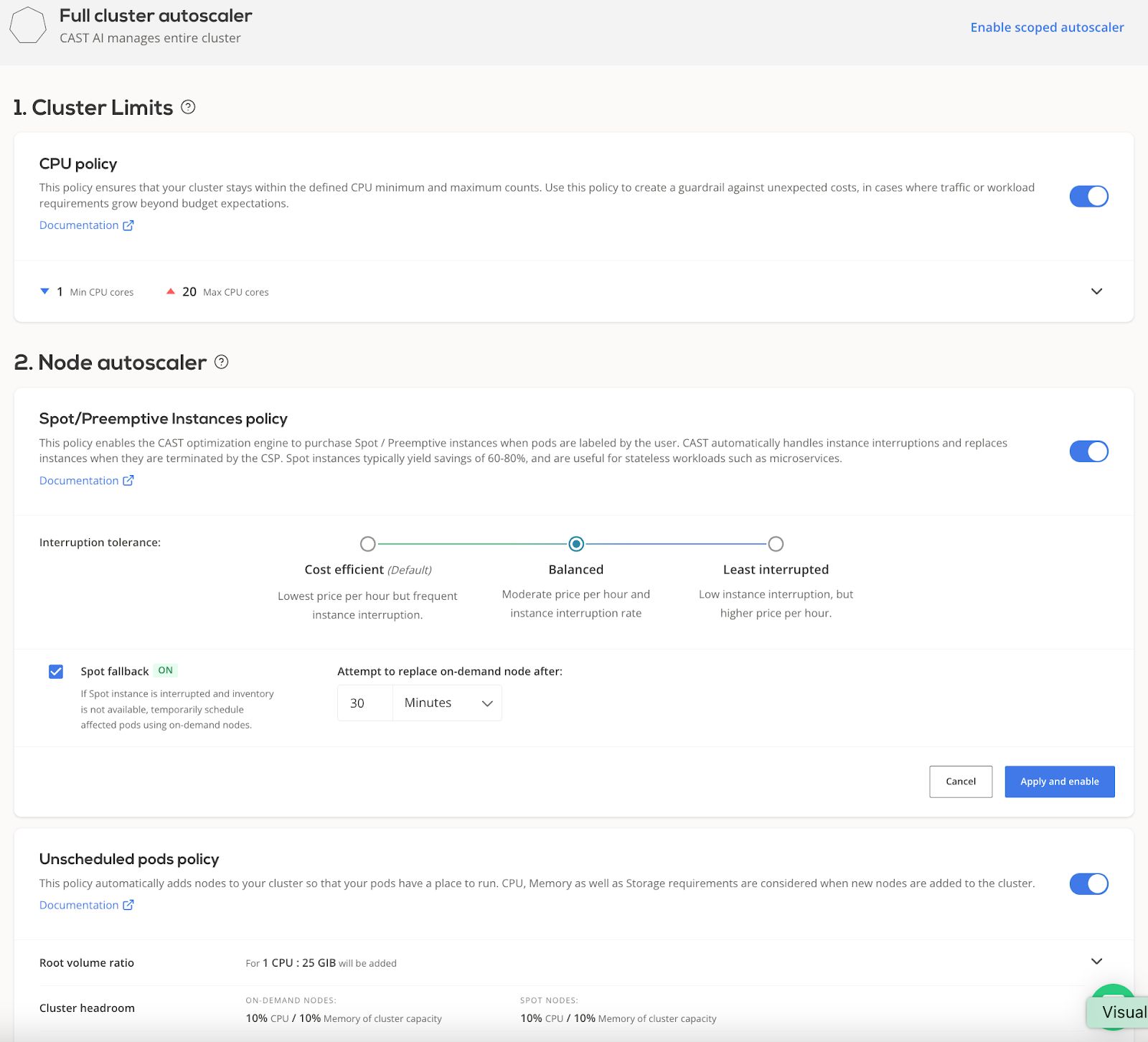
- Spot fallback – this feature guarantees that workloads designated for spot instances always have the capacity to run, even if no spot instances are available at the time. To keep workloads running, CAST AI provisions a temporary on-demand node and uses it to schedule the workloads, checking for spot availability every 30 minutes.
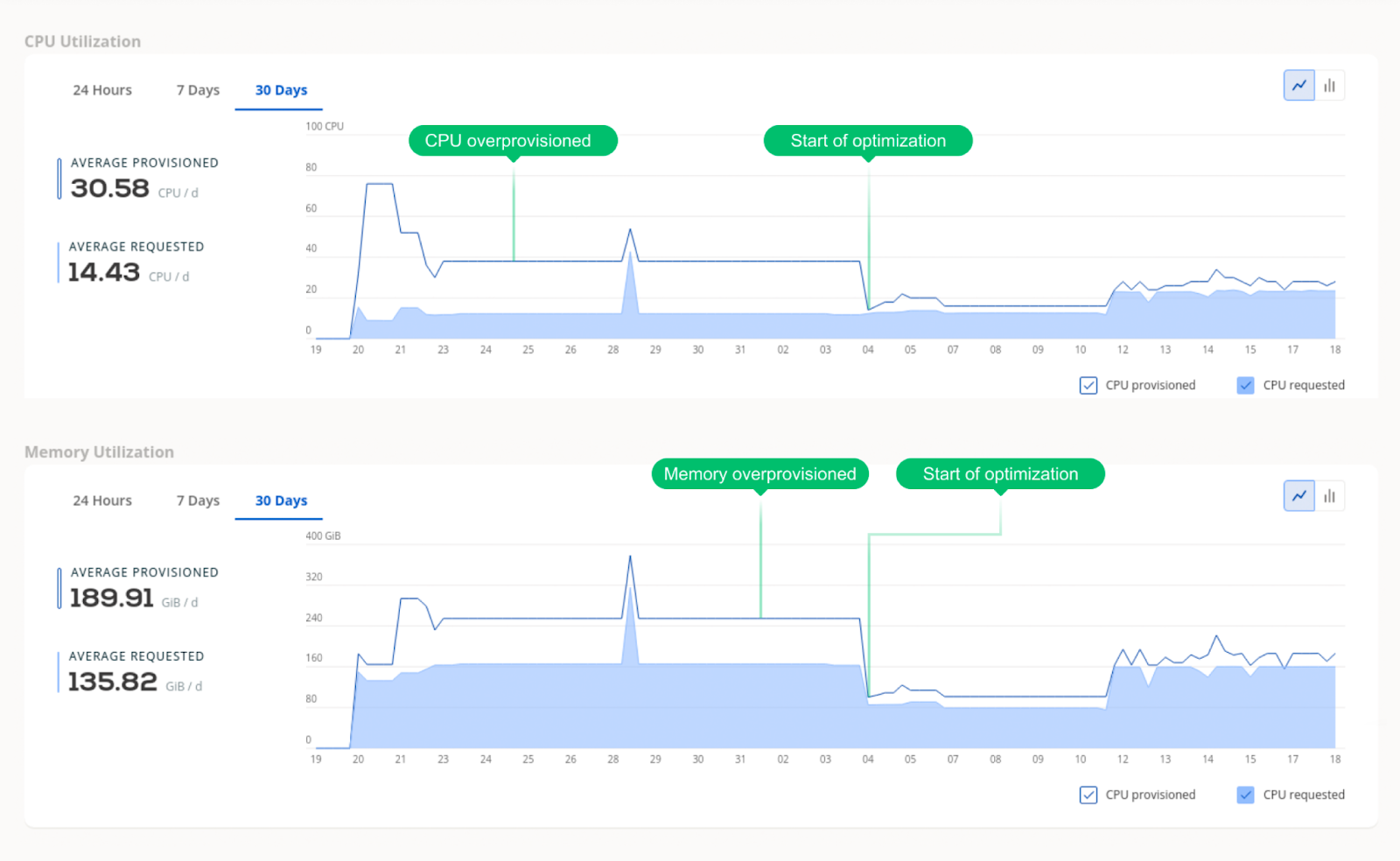
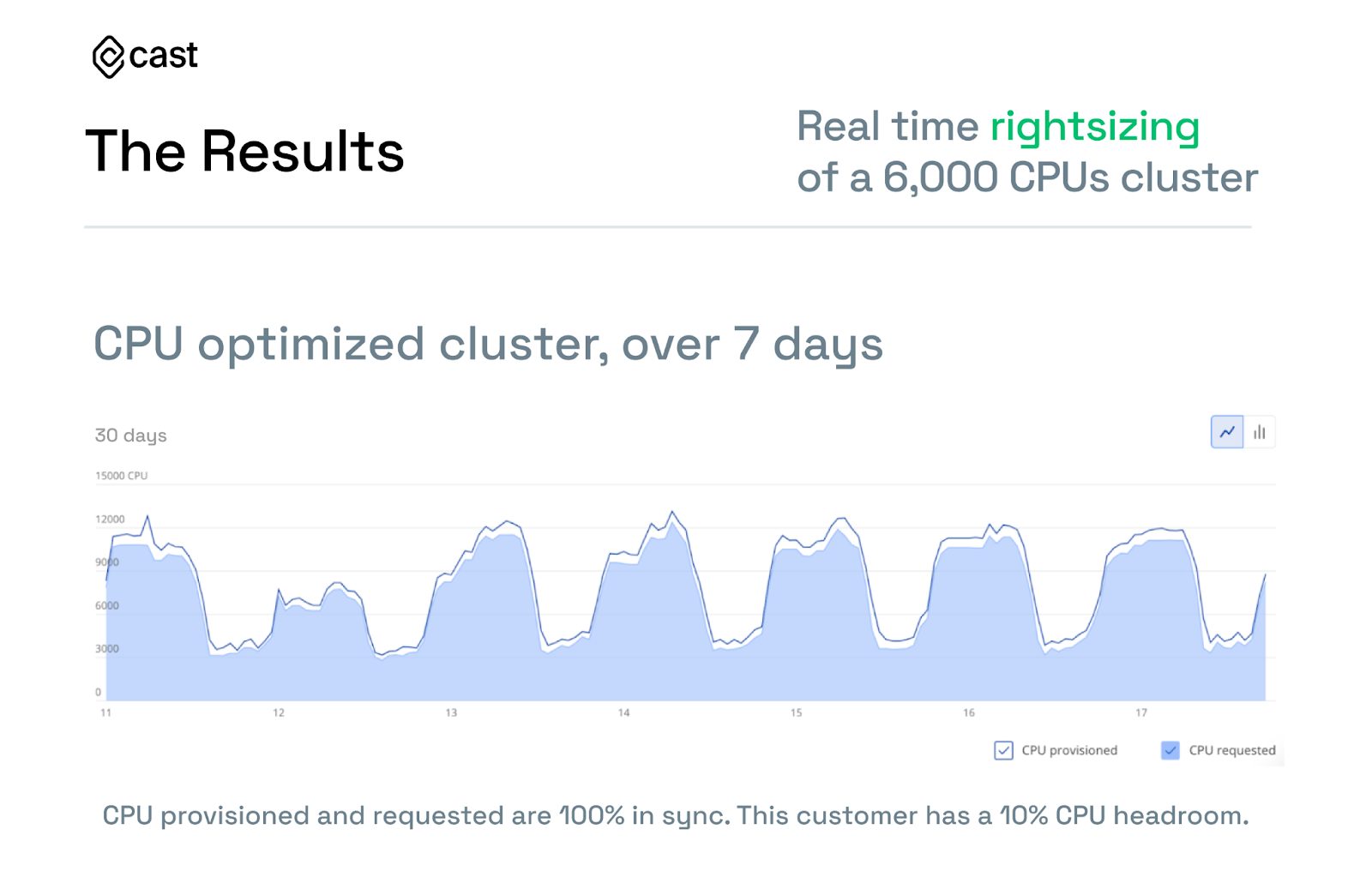
Take a look at this graph showing the difference between resources requested vs. provisioned (for both CPU and memory). Notice how it shrank once the team turned optimization on.
How to optimize an AKS cluster in less than 15 min with Advanced Autoscaler
CAST AI first finds out what resources your application needs, identifies the best combination of resources, optimizes your Kubernetes setup, and then constantly monitors for any changes, adjusting the choice and number of resources to the application’s requirements.
Step 1: Analysis
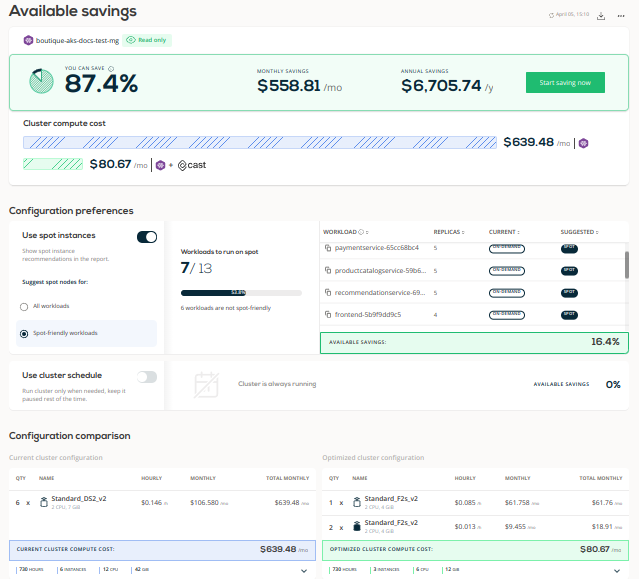
The analysis phase identifies potential savings – a combination of rightsizing and a better selection of virtual machines for the application.
In our test scenario, CAST AI determined that the cluster would achieve the same performance with 6 CPUs and 12GB of RAM instead of the 12 and 42 it was currently using. CAST AI also suggested replacing some instances with more cost-effective spot instances options.
The analysis concluded that by moving to this configuration, the cluster cost should drop from $639.48 to $80.67 per month (87.4% of savings).
Around 70% of the savings come from rightsizing – we reduce the cluster by half (from 12 to 6 CPUs). Replacing the existing VMs for new and cheaper ones and both of them are spot instances (16,4% of more savings)
Step 2: Instant optimization – Rebalancing
Once the analysis phase is completed, CAST AI is activated and moves to the next stage called rebalancing. The platform automatically transforms the old infrastructure into a new one that is cost-optimized.
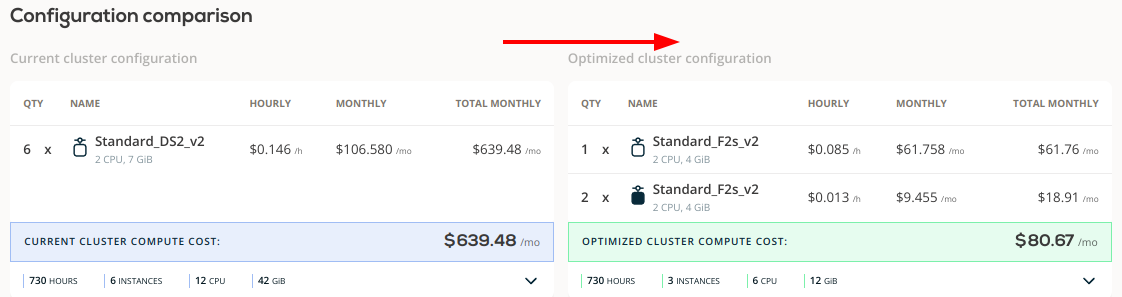
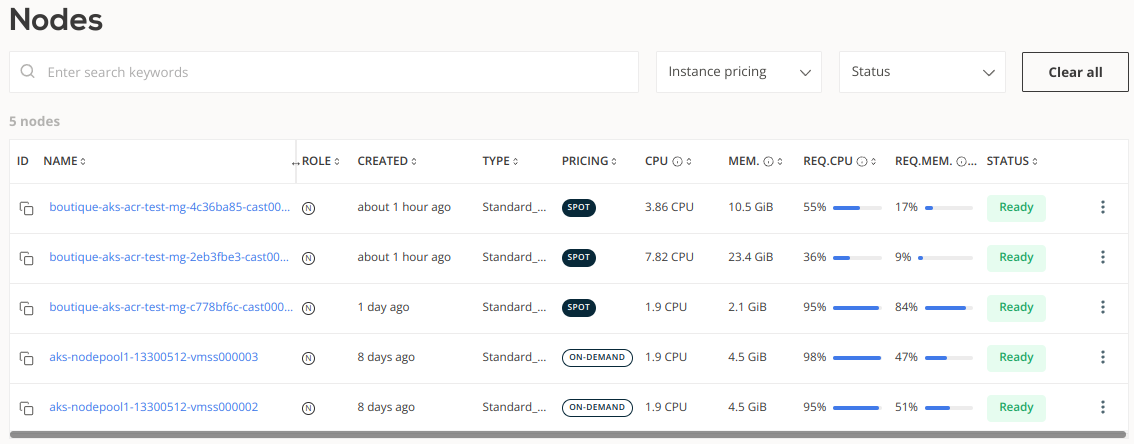
As indicated in the analysis, the AKS cluster was rebalanced from 6 Standard_DS2_v2 instances to just 1 on-demand instance and 2 spot instances. Its monthly cost dropped from $639.48 to $80.67. The entire process of rebalancing took 2 minutes and 43 seconds.
Users often schedule rebalancing to be carried out automatically once a day, week, or month. This is done on a schedule or via Terraform as part of the CI/CD pipeline.


Step 3: Autoscaling
Once you achieve an optimized state, CAST AI uses smart autoscaling mechanisms that continuously optimize your cluster.
You get optimized with rebalancing and stay continuously optimized thanks to smart autoscaling.
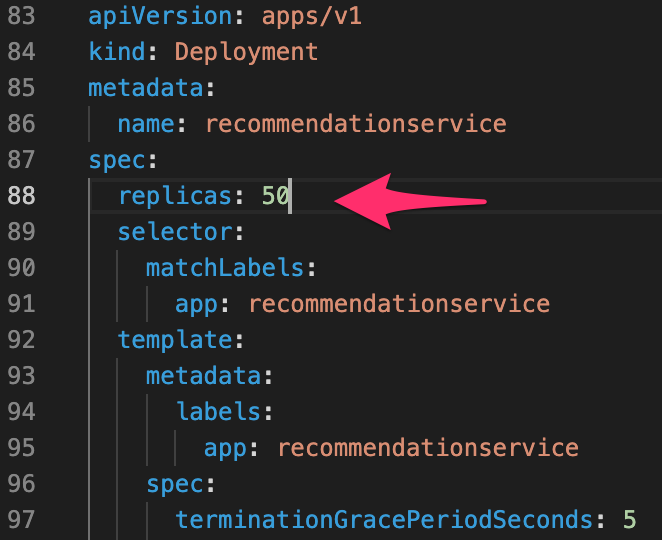
Here’s how Advanced Autoscaling works. For example, we set the number of replicas to a container to 50 after rebalancing.

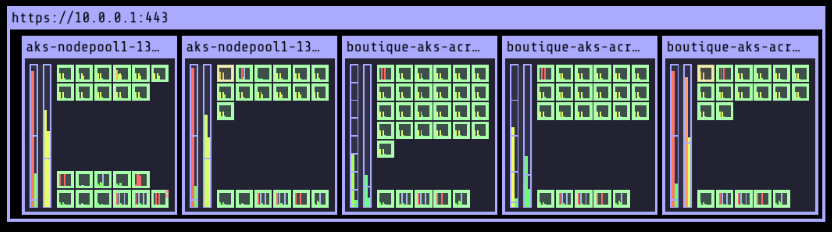
In less than a minute, CAST AI automatically added new nodes (compute instances) to the cluster. The engine decided to add 1 Standard_NV8as_v4 and 1 Standard_NV4as_v4, which were the most cost-effective spot instances at this time in the “East US region.”
Now the cluster has 5 nodes.
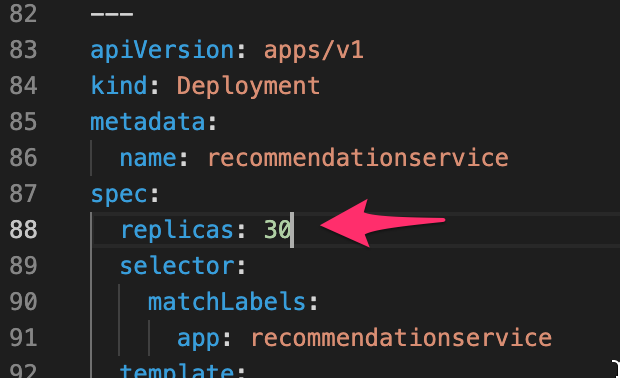
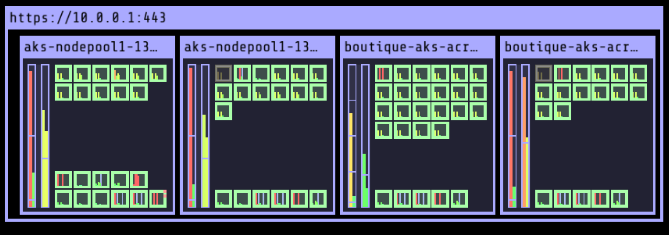
After we reduce the number of container replicas from 50 to 30, CAST AI automatically resizes the cluster by replacing the Standard_NV8as_v4 with a cheaper instance, Standard_F2s_v2:
The cluster now consists of 4 nodes. You can see that it reached the ideal configuration and is 100% optimized. This is how the Advanced Autoscaler enables continuous optimization.
In order to show different results, we increase/decrease the replica account of one of the deployments but this is a process that will be automatically handled by CAST AI according to your cluster necessities.
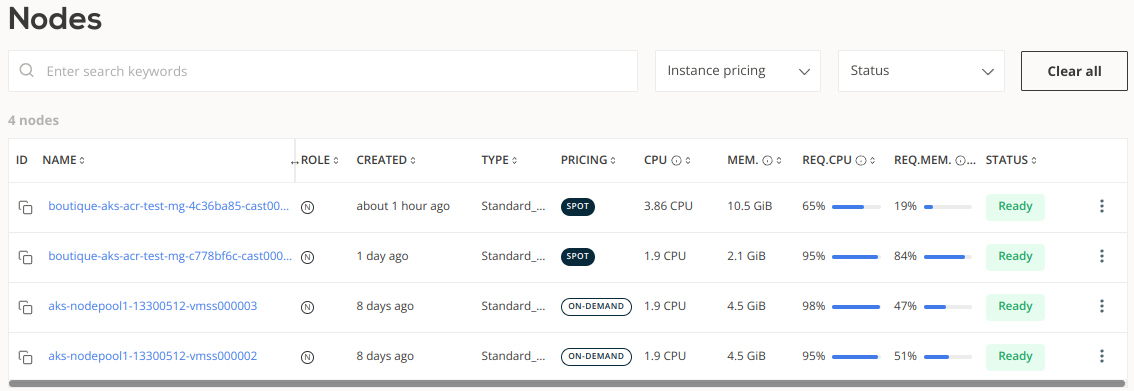
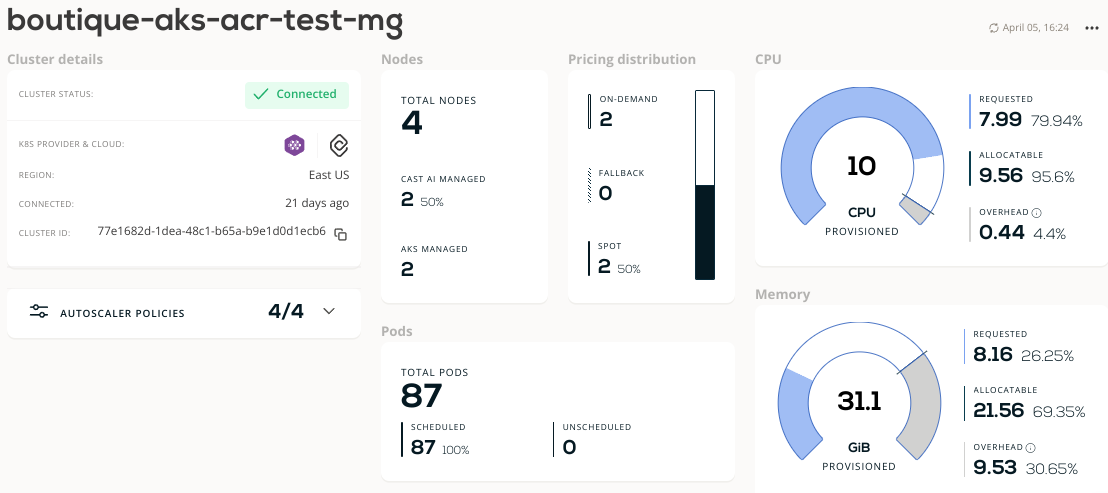
The autoscaler mechanism isn’t a black box. You can see all the options that regulate how CAST AI automatically adds and manages new nodes, including spot instances and potential interruptions, in the settings.
Once the process is done and CAST AI keeps optimizing your cluster, it’s common for our clients to see utilization like this:
Over to you
You can start with a free savings report to determine your savings potential before committing to any automation.



