
Before the rise of DevOps automation tools, the landscape of Kubernetes infrastructure management demanded meticulous manual input for every decision about instances, availability zones, families, and sizes.
Engineers spent hours, if not days, setting requests and limits and navigating a labyrinth of cloud provider offerings. Despite all this effort, the actual cost implications of Kubernetes clusters remained a mystery.
Engrossed in technical implementation details, DevOps teams found themselves disconnected from their projects’ financial journey. Manual Kubernetes management became not just a technical challenge but a strategic setback.
What are DevOps teams’ most time-consuming challenges when managing K8s – and how can you solve them?
4 reasons why manual Kubernetes management doesn’t work
1. Cloud billing is too complex and time-consuming to decipher
Take a peek at your cloud bill; it’s bound to be difficult to grasp. Each service has a specific billing measure, so understanding your consumption to the point where you can make solid projections is overwhelming.
If many teams or departments contribute to a single bill, you must understand who is using which resources to hold them accountable for the expenditures.
Cost allocation is challenging, particularly for dynamic Kubernetes systems. Imagine doing it all manually for multiple teams or cloud services!
2. Forecasting frequently relies on guesswork
To predict your future resource demands, DevOps engineers take the following steps:
- Start by getting visibility – Evaluate your use records to learn about patterns in spending.
- Identify peak resource utilization scenarios – Use periodic analytics and run reports over your usage data.
- Consider additional data types, such as seasonal client demand trends – Do they match your peak resource usage? If so, you may be able to identify them beforehand.
- Monitor resource use reports regularly and create alarms.
- Measure application- or workload-specific expenses to create an application-level cost strategy.
- Calculate the total cost of ownership for your cloud infrastructure.
- Analyze cloud providers’ pricing strategies and precisely anticipate capacity requirements over time.
- Gather all of this information in one place to better understand your charges.
Many of the tasks listed above are ongoing rather than one-time. Consider how long it would take to do all these steps manually.
3. Choosing the right instance type and size is a nightmare
AWS has hundreds of compute instances on offer. Good luck analyzing them all manually!
To choose the best virtual machine for your workload, you’re looking at the following tasks:
- Define your minimum needs for all computational dimensions, including CPU (architecture, count, and processor type), memory, SSD, and network connectivity.
- Choose the appropriate instance type from various CPU, memory, storage, and networking configurations.
- Select the size of your instance to ensure that it can grow your resources to meet your workload’s needs.
- Once you’ve decided on whatever instances you want, investigate the various pricing models available for AWS, which include On-Demand, Reserved Instances, Savings Plans, Spot Instances, and Dedicated Hosts. Each has advantages and disadvantages, and your choice will significantly influence your cloud cost (primarily computing).
And all of this must be done every time you pick an instance for your workloads. This is why resource selection makes for such a compelling use case for DevOps automation.
4. Using Spot instances manually is risky
Purchasing spare capacity from AWS and other big cloud providers is smart. Spot instances or VMs save up to 90% off the on-demand price. But there is a catch: the provider may reclaim these resources anytime, with just 30 seconds or 2 minutes’ notice. Your application should be prepared for this.
Managing spot instances manually may look like this:
- Check if your workload is ready for a Spot instance. Can it handle interruptions? How long does the job take to complete? Is the task important to the application? Answering these and other questions can help qualify a workload for Spot instances.
- Next, review the cloud provider’s offer. It’s a good idea to explore less popular instance types because they often have fewer interruptions and can operate stably for longer periods of time.
- Before selecting an instance, check its frequency of interruption.
- Now, it’s time to place your bid. Set the maximum amount you’re prepared to pay for that Spot instance; it will only be active if the marketplace price matches your bid (or is lower).
- The rule of thumb here is to put the maximum price at the level of on-demand pricing, so double-check that as well. If you specify a custom amount and the price of the Spot instance rises, your workload will be interrupted.
- Manage Spot instances in groups to request numerous instance types simultaneously, increasing your chances of obtaining a Spot instance.
For everything to work smoothly, expect a large amount of manual configuration, setup, and upkeep.
This is what DevOps automation brings to K8s management
When we launched CAST AI DevOps automation features, the game changed entirely. Imagine a world where all those intricate details around resource provisioning, scaling, and decommissioning are handled automatically. Engineers are liberated from the shackles of low-level management and free to focus on what truly matters: mission-critical initiatives that propel the business forward.
This isn’t just about saving time. It’s a paradigm shift in how we deploy and manage Kubernetes.
The reality is that the complexity and sheer number of possible instance permutations, combined with the rapid pace of technological change, make manual configurations cumbersome and less effective. Automated systems excel by analyzing and adjusting these variables in real time, ensuring businesses grow cost-effectively.
With CAST AI, the entire setup is designed to run with minimal human effort, from selecting the optimal mix of instances and managing resources efficiently to ensuring cost-effectiveness without manual intervention.
This is the essence of leveraging AI in cloud cost management. It’s not just about automating tasks; it’s about reimagining the engineer’s role in the cloud era.
By removing the burden of repetitive, volume-intensive work, automating DevOps tasks paves the way for creativity and innovation. Engineers can now dedicate their expertise to solving higher-order problems, crafting new features, and enhancing customer value.
Real-life example of DevOps automation: How Akamai achieved 40-70% cloud savings
Akamai is one of the world’s biggest and most reliable cloud delivery systems, with over 25 years of expertise assisting companies in delivering secure digital experiences. Akamai has a large and complex cloud infrastructure hosted by a major cloud provider, which powers services offered to the most demanding clients under rigorous SLAs.
Challenge: Optimizing infrastructure without any impact on availability
The company was searching for a Kubernetes automation platform that would reduce the expenses of keeping up its core infrastructure by scaling apps up and down in response to continually and, at times, radically shifting demand.
CAST AI provided a robust set of features that were perfectly suited to Akamai’s use cases and requirements, including bin packing to maximize resource utilization, automatic selection of the most cost-efficient compute instances, Spot instance automation throughout the instance lifecycle, and in-depth Kubernetes cost analytics.
Results: 40-70% of cost savings and greater engineer productivity
Akamai achieved 40-70% savings after adopting CAST AI, depending on the workload. The platform’s automated features also resulted in significant time savings, allowing engineers to concentrate on other important areas, such as building new consumer services.
The core savings we got are just brilliant, falling between 40-70%, depending on the workload. But that’s not the full story.
Before implementing CAST AI, my team was constantly moving around knobs and switches to make sure that our production environments and customers were up to par with the service we needed to invest in.
Now engineers have more bandwidth to focus on other areas they couldn’t invest in before, like releasing features faster for our customers.
Dekel Shavit, Senior Director of Engineering at Akamai
DevOps automation in action: autoscaling
The graph below shows how the CAST AI autoscaler scales cloud resources up and down in response to real-time demand, giving enough headroom to meet the application’s requirements.
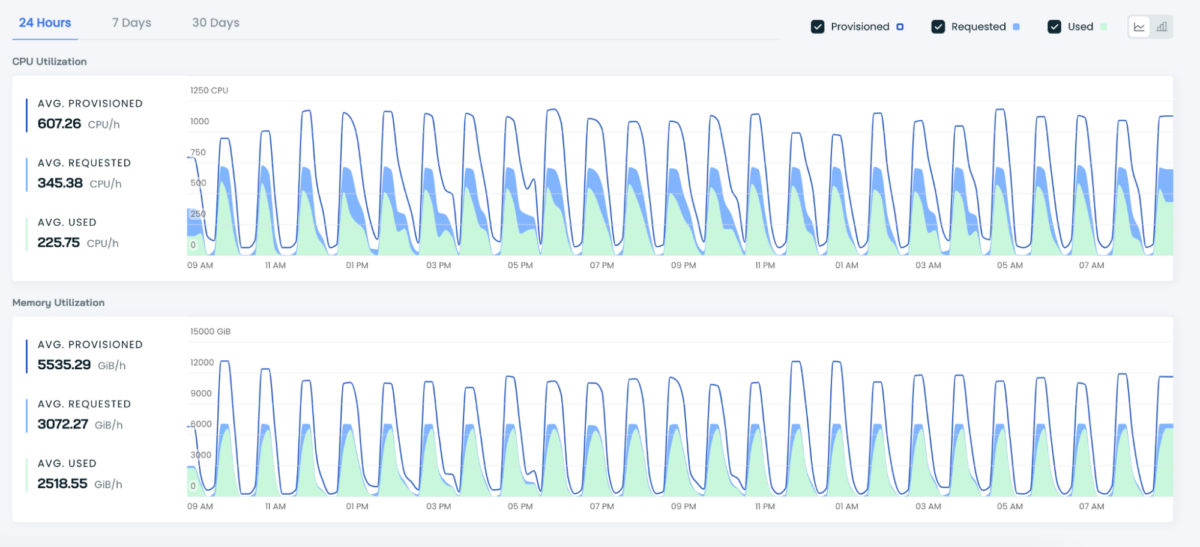
DevOps teams need a tool that not only enhances efficiency but also unlocks the creative potential of engineers by offloading monotonous and complex tasks onto an intelligent system.
Watch a demo to see how CAST AI could help your teams become more efficient, productive, and happier while contributing to your business growth.



