Company
Heureka Group is Central Europe’s leading price comparison platform and online shopping advisor, making online shopping easier for millions of users every day. The company operates in nine Central and Eastern European countries, attracting over 23 million visitors monthly and partnering with a network of more than 55,000 online stores.
Challenge
Heureka used Google Cloud’s native autoscaler, which often overprovisioned nodes, leaving over 40% of headroom – resources Heureka’s team never used but had to pay for. This prompted the search for an autoscaling solution to dynamically adjust the resources provisioned for clusters and workloads.
Solution
Cast AI’s autoscaling capabilities at the node and workload levels help Heureka scale cost-efficiently. The company uses automated scaling and bin packing mechanisms to provision just enough resources to ensure excellent performance without incurring a high cloud bill.
Results
- 30% cloud cost savings achieved across Dev and Pre-prod clusters
- Cost-efficient node autoscaling with minimum headroom
- Full control over automation mechanisms
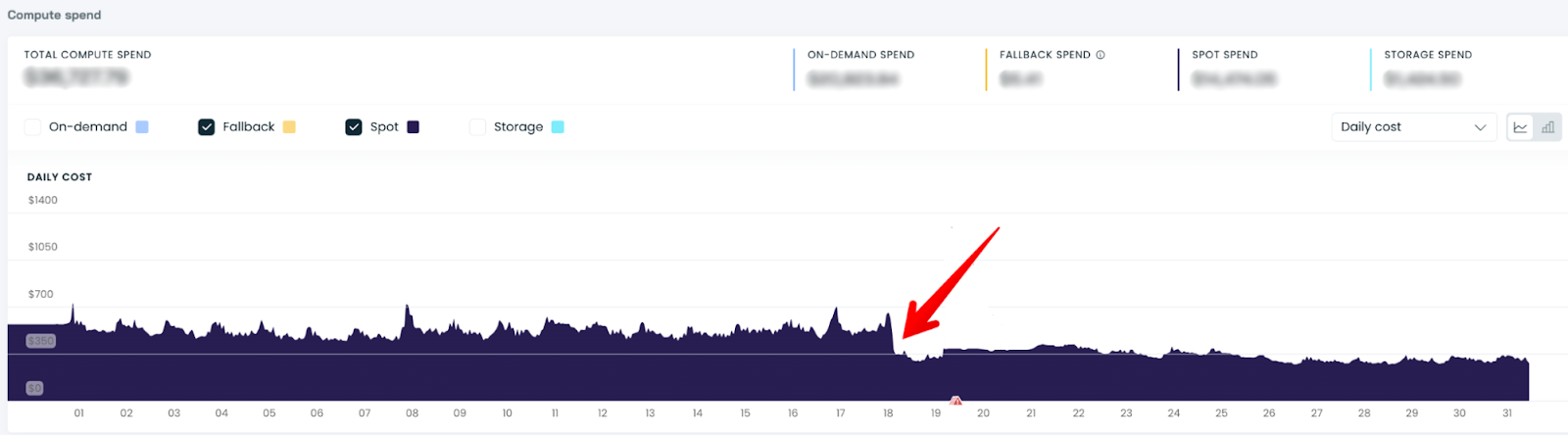
Bin packing Spot VMs in the Dev and Pre-prod cluster for 30% savings
Since implementing Cast, Heureka has seen a 30% drop in compute costs in the Dev cluster. This was achieved by bin packing Spot-friendly workloads (stateless workloads that tolerate interruptions) and quickly removing the empty Spot nodes to drive down the number of provisioned CPUs.

The Cast autoscaler unlocked more savings by moving Spot-friendly workloads already deployed on Spot VMs to cheaper families while maintaining service uptime and application performance.
Cast helped Heureka reduce the cost of its Dev and Pre-prod clusters by bin packing workloads and consolidating the clusters into fewer spot nodes to reduce the number of wasted CPUs:
Improved resource utilization in the Production cluster
The company also implemented the Partial Spot policy for Production workloads to cut costs without sacrificing the stability of the business-critical workloads. The following graph shows how Cast provisioned enough capacity to handle scaling events seamlessly.
Spot VM diversification
To ensure Spot instance availability and maintain optimal cost, the Cast autoscaler selects a diversified pool of Spot instance types. The following node list shows the different types of instances provisioned for the Dev cluster.
If a specific Spot VM family is unavailable, Cast automatically picks other instance families or falls back to on-demand instances, with no human intervention needed.
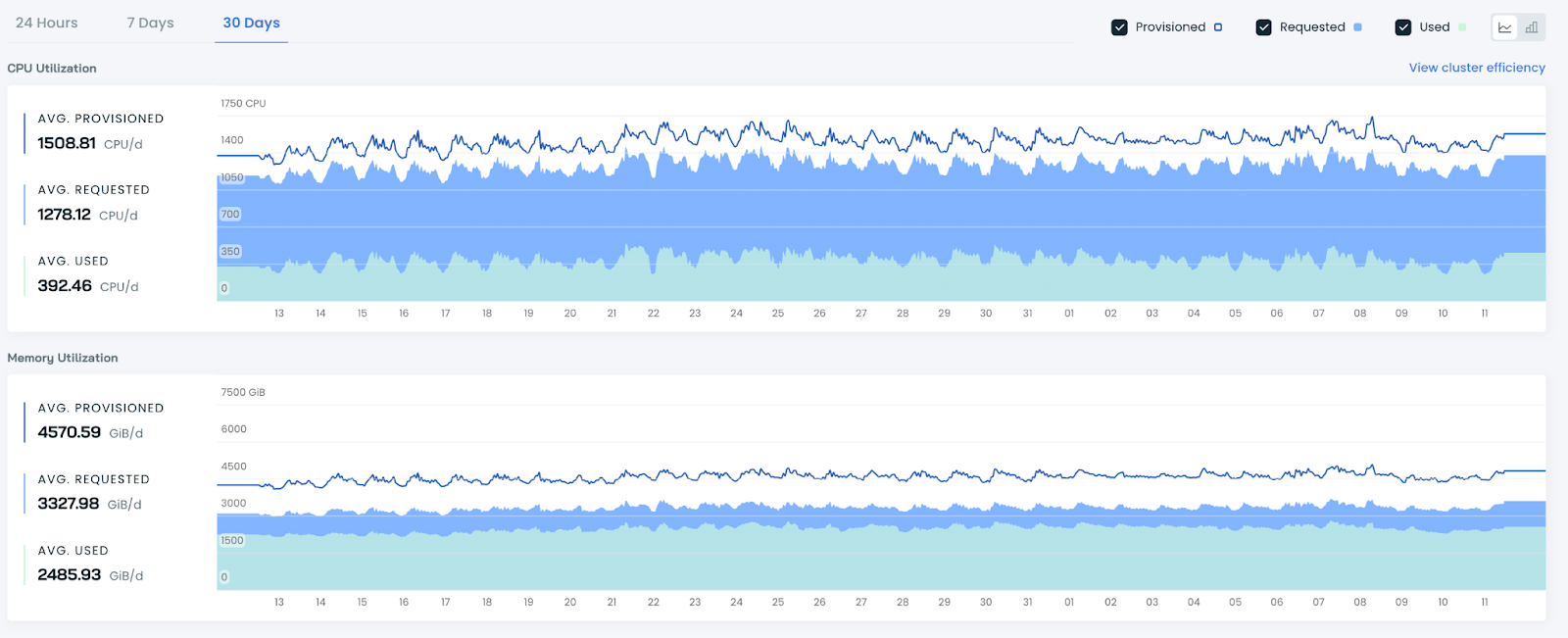
Cast comes with a powerful bin packing capability that consolidates the cluster into fewer nodes, reducing wasted CPUs at the node level. The graph above shows how the nodes were bin packed to reach 99% utilization for both CPU and Memory.
When you have an application that dynamically scales, you often end up with excess headroom. For example, if your application scales at 60% usage, the remaining 40% goes unused because once you reach that, it scales up again, leaving another 40% buffer that you still pay for.
Additionally, the Google autoscaler isn’t very strict; it leaves a lot of headroom on the nodes, meaning you’re paying for around 15-20% more computational power than needed because the autoscaler doesn’t reduce that capacity efficiently.
Cast AI addressed these issues by reducing headroom on both the physical nodes and the application side.
Martin Petak,
Infrastructure Team Lead at Heureka Group
In the retail world, scalability is key
Which requirements must your infrastructure meet to support your business operations as a retail company?
Our infrastructure must be highly scalable due to fluctuating traffic throughout the day and year, especially during peak periods like Christmas, when traffic can increase by over 50%.
Traffic surges start in early October as people shop for presents, ramping up through November and continuing even on Christmas Eve. After Christmas, e-shops offer discounts, driving traffic until late January, when our peak season typically ends.
That’s because Heureka isn’t just for buying but also for finding gifts. Users can get personalized suggestions and compare prices. You can tell one of our advisors, “Hey, I’m looking for a present for my mother, and she likes something like that,” and Heureka will give you some suggestions about what the right present would be.
And you don’t want to bother with scaling the infrastructure up and down manually to meet this changing demand.
What challenges have you encountered along the way?
We were facing two challenges:
Challenge 1: Scaling the infrastructure up and down efficiently
From an infrastructure point of view, scaling was quite smooth. We started with Google Cloud Platform and used its native autoscaler, which worked well.
However, the challenge lies in preparing the application for sudden traffic spikes. Sometimes, traffic surges happen too quickly, or bots may start scraping the site, causing sharp, unnatural spikes that don’t follow the typical human user curve.
In such cases, some applications might struggle to handle the traffic fast enough. This has been a challenge, but it’s primarily a concern for our development team rather than the infrastructure side.
Challenge 2: Cost optimization
When you have an application that dynamically scales, you often end up with excess headroom. For example, if your application scales at 60% usage, the remaining 40% goes unused because once you reach that, it scales up again, leaving another 40% buffer that you still pay for.
Additionally, the Google autoscaler isn’t very strict; it leaves a lot of headroom on the nodes, meaning you’re paying for around 15-20% more computational power than needed because the autoscaler doesn’t reduce that capacity efficiently.
Cast AI addressed these issues by reducing headroom on both the physical nodes and the application side.
Looking for a cost-efficient autoscaler
Which solutions did you evaluate before betting on Cast?
We initially tried some homemade solutions, which is why we appreciate Cast so much. One feature was its open-source component for network observability, egressd.
This allowed us to deploy it ourselves and monitor the data. We first aimed to tackle the network, and while our efforts yielded some results, they didn’t meet our expectations.
We experimented with internal FinOps hackathons and tools like Descheduler to make the GCP autoscaler more aggressive in terminating idle nodes. However, we still found that many paid resources remained unused.
How did you get into a POC with Cast?
We received a recommendation from our partner, Revolgy, a company that supports us with Google Cloud Platform services. Given our long-standing relationship with them, we decided to try their suggestion and took Cast for a spin. We set up demo clusters and reviewed the data they produced, and everything looked good. After that, we proceeded with the onboarding.
What was the onboarding process like?
The dev cluster’s initial onboarding was very fast. Fully onboarding might have taken a few weeks or up to two months, but the delays were mostly on our side.
For dev, it was quick since we handled everything manually during the POC phase. However, we exclusively use infrastructure as code, so we wanted everything integrated into Terraform for the pre-production environment. This required removing Cast from Dev, adding it as code, using the same code for pre-prod, evaluating it, and then moving to production.
So, if by “complete onboarding,” you mean having production fully managed by Cast, then yes, it took us a few months.
Eliminating overprovisioning and achieving 30% of cost savings
Which Cast features have you been using and what results did they generate?
The main features we’re using are autoscaling and Spot VM automation. In our Kubernetes clusters, we have one cluster per environment, shared across all workloads. Because of this, we have multiple node pools—some for stable workloads, some for dynamic workloads that can run on Spot VMs, and some with special requirements like physical disks.
With Cast AI, we only enabled autoscaling for the spot node pool, which handles dynamic workloads. In Dev and Pre-prod, this reduced the resources needed for those node pools by about 33%.
In Production, the reduction was smaller, but there are additional features we haven’t yet had time to implement that could further optimize it.
What level of cost savings were you able to achieve across your Kubernetes clusters?
Looking at all of our clusters, we achieved around 30% of cost savings.
The savings were significantly higher in Dev and Pre-prod environments than the Cast fee. At this point – before we implement the other Cast features – Cast basically pays for itself.
Reaping the benefits of automation
What benefits did Cast bring to your team?
Node rightsizing
By rightsizing, I mean that Cast provisions nodes with just the right amount of resources needed at a given time. This also includes handling Spot VM interruptions without headaches.
Ability to dynamically change the setup
Another feature I like is how dynamically I can make changes. For example, when we need to change the node type or adjust the minimum and maximum CPU, memory, or load family, it’s all very flexible. I appreciate how easily I can modify these settings, making it a key benefit for us.
Recommendations for the workload rightsizing
Currently, we are exploring the recommendations available for setting workload requests and limits – until we start to fully use the automated workload rightsizing. While it’s our developers who are responsible for their workloads, the infrastructure team also manages shared services inside Kubernetes. We’re leveraging the workload suggestions to optimize our operations and gain an advantage
Did you see any other benefits of Cast?
When we started using Cast in production, we gained some valuable insights. Initially, we faced significant issues with high latencies; the application was slow to respond even though we had overprovisioned resources.
This prompted us to investigate further, leading to a better understanding of the differences between GCP instances, particularly regarding the speed of their CPUs and how our application responds to them. This knowledge has been a significant change for us moving forward.
What was the support like throughout the implementation and afterwards?
In one word, I would say: superb.
The Cast team was always ready when we needed to move forward.
During that incident with higher application latency due to slower nodes, I reached out because I was unsure of the next steps. Within 10 minutes, a team was on a call to investigate, and it was actually Cast’s suggestion that led us to the solution. The issue wasn’t with Cast itself but rather with our settings. So, yes, I’m very satisfied.
Towards a fully automated optimization setup
What optimization steps are you planning to take with Cast?
Automated workload rightsizing is an area we haven’t had the proper time to implement yet. One reason is that the infrastructure team is not responsible for the workloads.
At our company, developers write, build, and deploy their applications and handle their own calls regarding those applications. They are fully accountable for what they run while we focus on the tooling and shared resources. However, this division of responsibilities means it takes time for developers to find the opportunity to experiment with Cast for their workloads.
What kind of company would you recommend Cast to?
That’s a really interesting question. On the one hand, you don’t need extensive Kubernetes maturity to use Cast AI, as it assists you with various tasks. On the other hand, a company with a high level of Kubernetes experience would be able to utilize Cast even more effectively.
So, it’s beneficial for both scenarios. Cast provides reasonable defaults for those lacking experience, while experienced users can leverage it to its full potential.




