A Gartner survey of infrastructure and operations leaders revealed that 58% of them deal with insufficient skills and resources for cloud optimization on a regular day. What happens when the summer rolls around and engineers start taking time off en masse?

Every cloud operations team knows that summertime comes with changes in seasonal demand patterns.
On one hand, there are fewer engineers around to keep an eye on cloud resources. On the other, the demand for service might be lower because other people flock to vacation destinations as well.
Scaling cloud resources down in line with that changing demand is critical to keep your OPEX low and utilization high. But how do you make that happen when a big chunk of your team is out of the office?
How to manage the cloud when your engineers are gone
One proven method of bridging the cloud skills gap in the industry is using managed service providers and solutions. Such solutions bring know-how, process maturity, and established toolsets that improve cloud usage across many acres, from security to cost-efficiency.
Such solutions can help your team with both tactical and technical initiatives, providing expertise with specific cloud issues – for example, cloud cost management and optimization.
Many managed solutions rely on automation. The idea is to automate processes for repeatable tasks like resource provisioning or monitoring and free up engineers for other, more impactful activities. Instead of spending time on mundane, manual tasks, they can focus on more strategic work and increase system standardization while optimizing team resources.
The fintech company Delio automated the process of scaling Kubernetes clusters to get it done automatically in minutes, saving plenty of engineer time:
Before implementing CAST AI, bumping up an instance size was a bit of a pain. Now I can decide to add another instance or increase its size, and the platform does it automatically for me. We used to have four or five people involved in managing this, now they’re free to do other stuff, which is great.
Alex Le Peltier, Head of Technology Operations at Delio
Reduce capacity in times of low demand
Using an automation tool that comes with an abstraction layer frees teams from the complexity of dealing directly with cloud solutions. Shift to an out-of-the-box cloud setup that scales automatically and you’ll be on the way to smoother management and cost savings.
Every cloud operations team has this one task: provisioning cloud resources. And every team knows there’s much more to that than it seems. Typically, you need to:
- Identify the minimum requirements of the application across all compute dimensions including CPU (architecture, count, and the choice of processor), Memory, SSD, and network connectivity.
- Pick the right instance type from various combinations of CPU, memory, storage, and networking capacities. Sounds like a piece of cake? AWS has 400+ instances available!
- Select the instance size to make sure that it matches your application requirements and doesn’t break your wallet. You need to aim for just enough capacity, and that’s hard.
- Once you know which instances you need, it’s time to review different pricing models: on-demand, Reserved Instances, Savings Plans, spot instances, and dedicated hosts. Each comes with its pros and cons – and your choice will have a massive impact on your cloud bill.
Cloud automation solutions step in to handle all of these tasks:
- selecting the right cloud resources,
- rightsizing them to avoid overprovisioning,
- scaling them up and down in real time to match the changing demand,
- and decommissioning them they’re no longer needed (no more orphaned instances or shadow IT!).

Cloud operations teams know first-hand how much management overhead the cloud generates. No wonder mature, cloud-native companies like Delio use automation to free engineers from this burden.
“We were running on T-type EC2 instances and scaling them a lot during our operation. At the beginning, we used AWS autoscalers and then added Azure into the mix. Keeping an eye on it all became difficult. Are we using the right instances for the right job? Do we have to create more node groups? Is something not working because we’ve run out of space? Answering all of these questions and applying fixes became a time-consuming issue for our team,” said Alex Le Peltier.
Prepare your cloud infrastructure for the summer
Here’s how you prepare for the summer season: equip engineers with an automation solution and sleep well at night, knowing that your infrastructure is taken care of from a cost standpoint.
If you use Kubernetes, look into managed platforms that specialized in Kubernetes autoscaling. For example, CAST AI includes Kubernetes-specific automation mechanisms that make scaling up and down easier:
- Autoscaling – using business metrics, the platform generates the optimal number of required pod instances. Next, it scales the replica count of pods up and down and removes all pods if there’s no work to be done. This is how CAST AI ensures that the number of nodes in use matches the application’s requirements at all times.
- Headroom policy – what happens if a pod suddenly requests more CPU or memory than the resources available on any of the nodes? The autoscaler can easily match the demand by keeping a buffer of spare capacity.
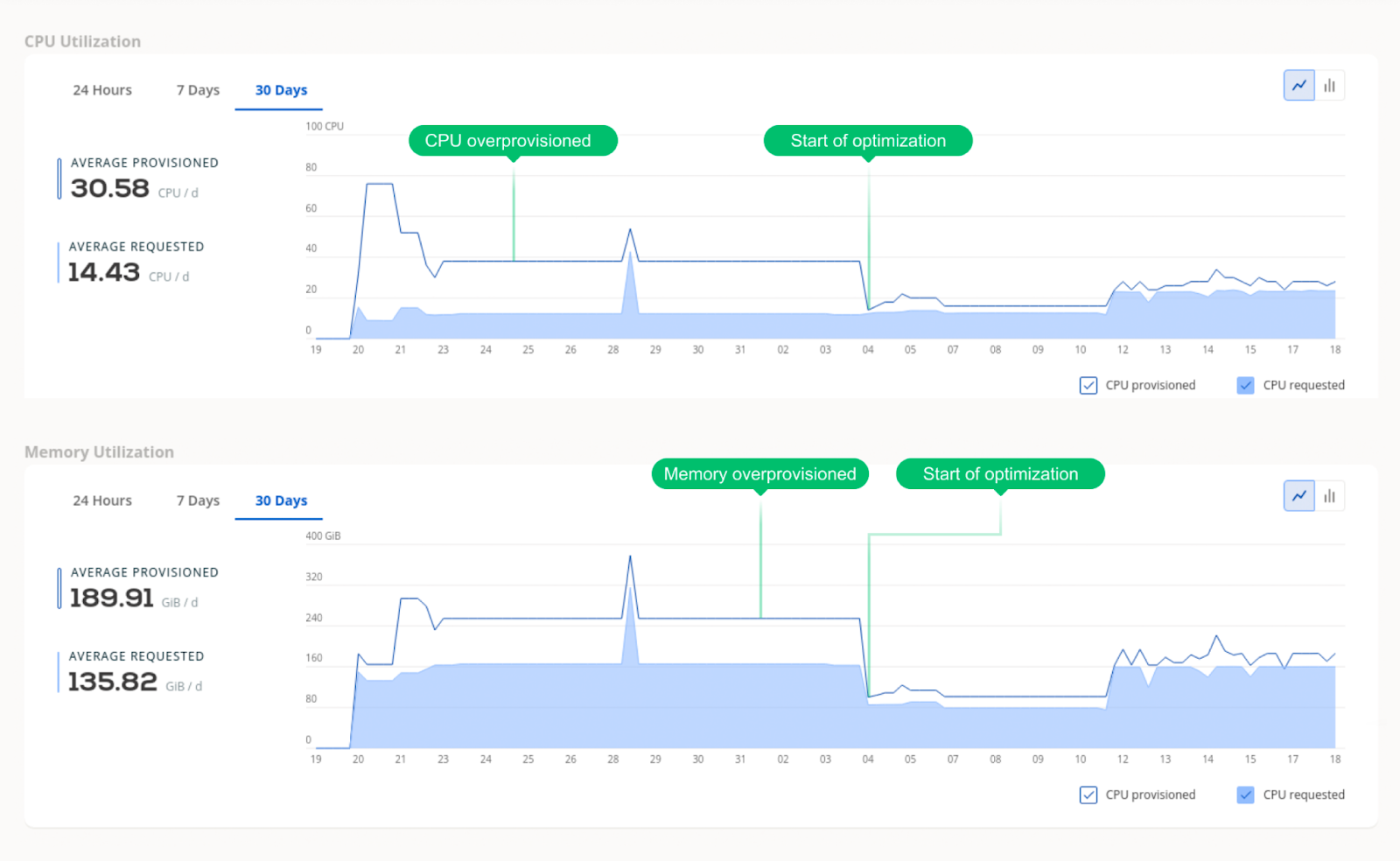
Check out this graph showing the difference between resources requested vs. provisioned (for both CPU and memory). See how it shrank once the team turned the automated scaling on?
Over to you
Check how well your cluster is doing in terms of autoscaling and cost-efficiency by running the free savings report – it works with Amazon EKS, Kops, GKE, and AKS.






Leave a reply