
“Kubernetes load balancer” is a pretty broad term that refers to multiple things. In this article, we will look at two types of load balancers: one used to expose Kubernetes services to the external world and another used by engineers to balance network traffic loads to those services.
Keep reading to get proven best practices for dealing with a Kubernetes load balancer.
What is a Kubernetes load balancer?
In Kubernetes, containers are grouped into pods with shared storage and network resources, as well as specifications for how to run these containers. A group of related pods can form a Kubernetes service.
Since pods aren’t persistent – Kubernetes creates and destroys them automatically – their IP addresses aren’t persistent either. To expose pods, you need to use a Kubernetes resource called Service.
A Kubernetes service allows you to expose a group of pods to external or internal usage. You can choose from a few types of services, so here’s a quick overview to get you started.
Overview of Kubernetes Services
ClusterIP – this is a default type of K8s service which exposes a set of pods only internally. Here’s an example YAML definition for the ClusterIP Service:
apiVersion: v1
kind: Service
metadata:
name: my-internal-service
spec:
selector:
app: my-app
type: ClusterIP
ports:
- name: http
port: 80
targetPort: 80
protocol: TCPClusterIP is used for internal application communication and is not available outside of the cluster.
NodePort – the Service exposes a given port on each Node IP in the cluster.
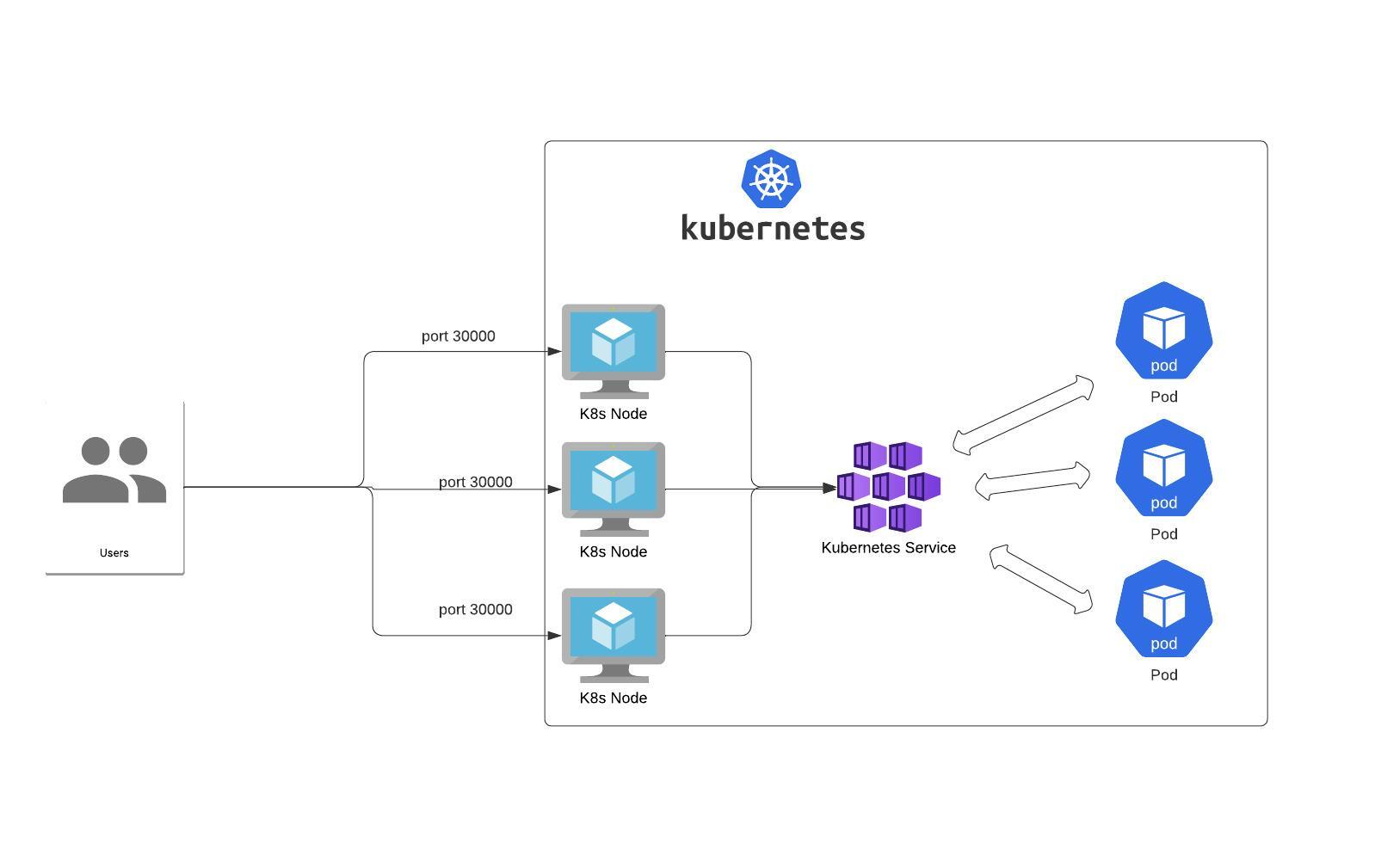
Example YAML definition:
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service
spec:
selector:
app: my-app
type: NodePort
ports:
- name: http
port: 80
targetPort: 80
nodePort: 30000
protocol: TCPNote that the NodePort Service has a lot of downsides:
- you can only have one service per port
- you can only use ports 30000–32767,
- if your Node/VM IP address changes, you need to deal with that.
That’s why it’s not recommended for production use cases.
LoadBalancer – this Service exposes a set of pods using an external load balancer. All managed Kubernetes offerings have their own implementation of it (for EKS you can use NLB, ALB, etc.)
In most cases, they’re created by the cloud provider. But there are also some projects that aim to expose it on bare metal clusters – metallb is a good example (I share more examples at the end of this article).
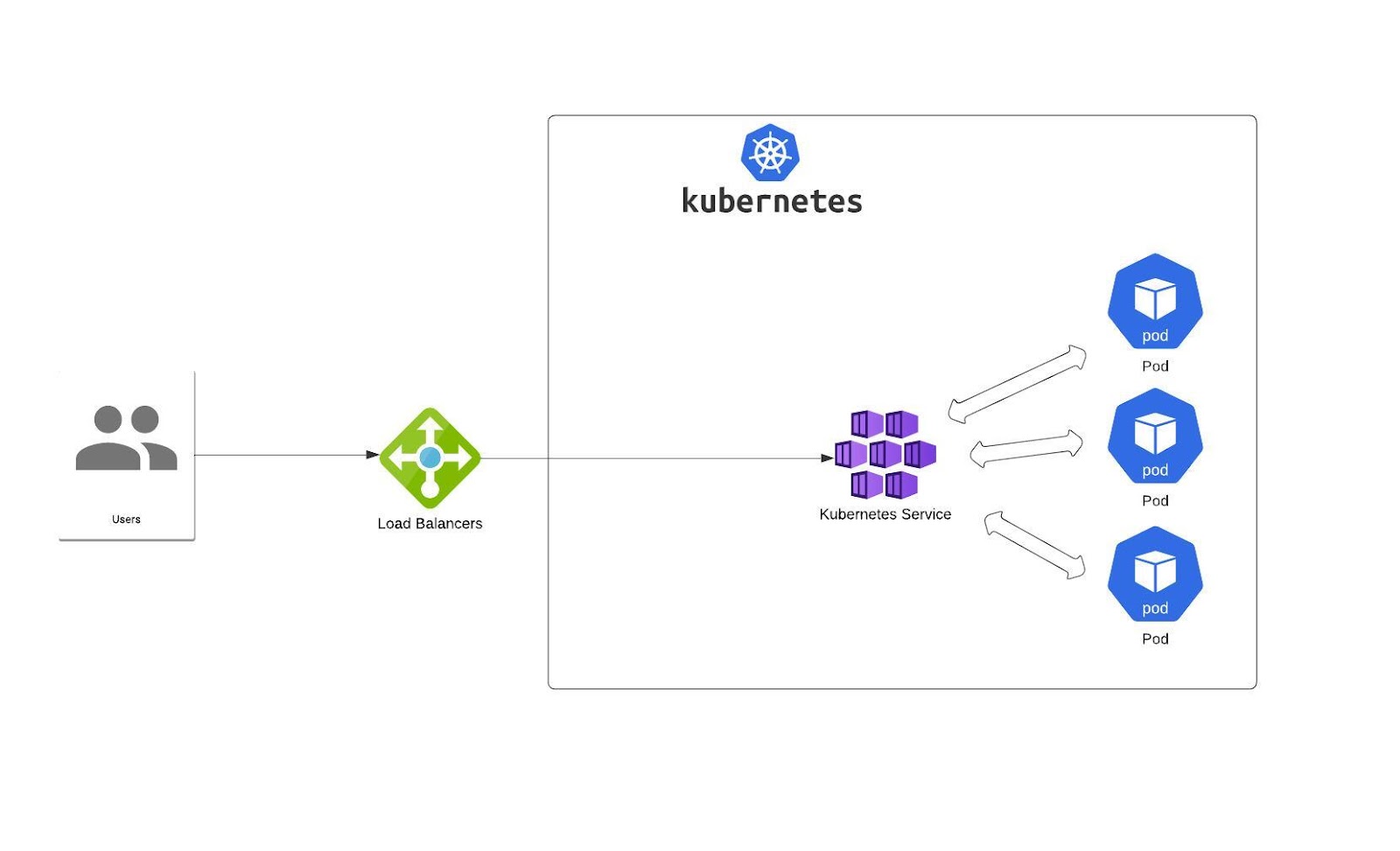
But that’s not the end of the story.
Kubernetes also has an API object called Ingress. Ingress is built on top of the Kubernetes Service (to expose Ingress, you need to use the Kubernetes Service). The main responsibility of Ingress is distributing network traffic to services according to predetermined routing rules or algorithms.
It also exposes pods to external traffic, usually via HTTP. Depending on your business goals and environment specifics, you can use different load distribution strategies.
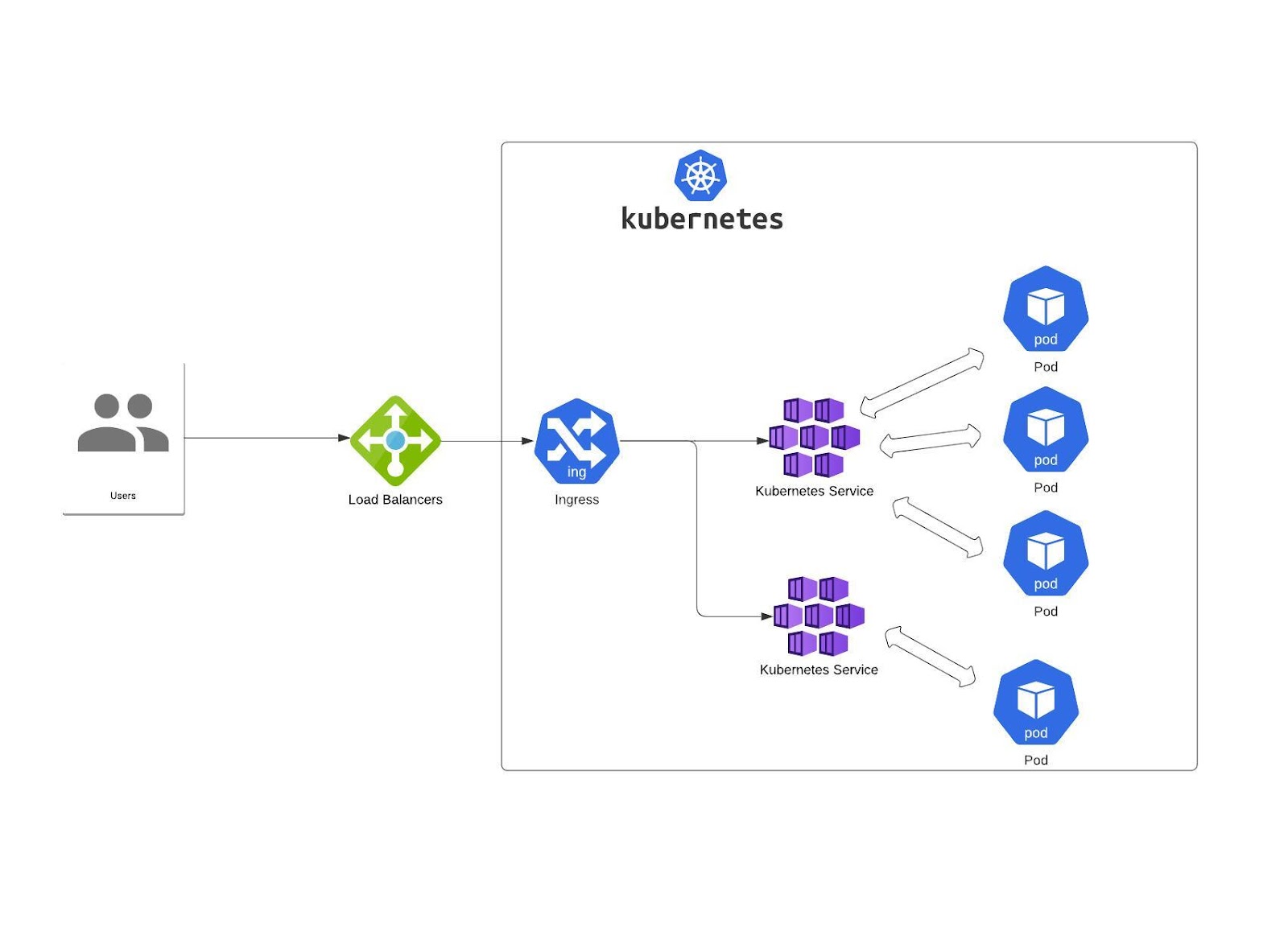
Example YAML definition:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx-example
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
service:
name: test
port:
number: 80Load balancer traffic distribution strategies
Efficient distribution of network traffic among several backend services is key to maximize scalability and availability.
You have a lot of freedom in load balancing external traffic to pods, but each strategy comes with its advantages and tradeoffs. It all depends on your load, requirements, and preferences.
The choice of the load balancing algorithm is one you should make carefully – otherwise, you’ll end up with an unbalanced load distribution or a single web server running hot.
Here’s a selection of load balancing algorithms you should consider.
Round Robin
Using this scheduling algorithm, you follow a sequence of eligible servers that get new connections. Note that this solution is static – it doesn’t really account for speed or performance variations among these individual servers. It simply makes sure that requests come to the servers in order.
Round robin is unable to differentiate between slow and fast servers, so it allocates an equal number of connections to each of them. If you’re expecting high-performance production traffic, it might not be the best choice.
L4 Round Robin load balancer
One of the basic load balancing tactics in Kubernetes. It fields all the requests sent to the service and routes them. The kube-proxy implements virtual IPs for services with the help of iptables rules, adding some complexity to the process. It also adds additional latency with every request, which might pile up into a problem if the number of services keeps growing.
L7 Round Robin load balancing
The L7 proxy directs traffic to Kubernetes pods by bypassing the kube-proxy via an API gateway and managing requests for available pods. The load balancer also tracks pods, which are available with the Kubernetes Endpoints API. When it receives a request for a given Kubernetes service, it round robins the request among the relevant pods to find an available one.
L4 kube-proxy and IPVS
By default, kube-proxy uses iptables for routing, but it can also use an IP Virtual Server (IPVS). The perk of IPVS is scalability: runs in O(1) time without being influenced by the number of routing rules required. This number is directly proportional to the number of services.
If you’re running a huge Kubernetes cluster with thousands of services, IPVS is a good option. Still, IPVS is L4-level routing, so it’s subject to some limitations.
Ring hash
This scheduling algorithm is based on a hash, which derives from a specified key. A hash allows the distribution of new connections across servers. Ring hash is a good solution for a large number of servers and dynamic content since it brings together load balancing and persistence. Many e-commerce applications or services that need a per-client state use it.
When a server needs to be added or taken away, consistent hashing doesn’t have to recalculate the whole hash table. So, it doesn’t affect other connections. Note that ring hash may add some latency to requests when running at scale. Also, the algorithm generates relatively large lookup tables that may not fit into your CPU processor cache.
Maglev
Similarly to ring hash, Maglev is a consistent hashing algorithm that was originally developed by Google. The idea behind it was increased speed over ring hash on hash table lookups. The other goal of its creators was to minimize the algorithm’s memory footprint.
If you decide to use Maglev for microservices, expect high costs that come from generating a lookup table when a node fails. Since K8s pods are relatively transient in nature, using Maglev might not be the best idea.
Least connection
This dynamic load balancing algorithm distributes client requests to pods with the lowest number of active connections and the smallest connection load. Thanks to this, it’s adaptive to slower or unhealthy servers. But when all of your pods are equally healthy, the load will be distributed equally.
Best practices for handling a Kubernetes load balancer
When implementing Kubernetes load balancers, take a few configuration steps to make sure your K8s deployment uses the load balancers you pick to the fullest.
Here are a few best practices for working with load balancers in Kubernetes.
Check whether the load balancer is enabled
This one seems too obvious to be included in this list, but it’s a key step. You need to have the service load balancer enabled in your K8s system. Your load balancer needs to support contained environments and service discovery. Also, your application should be designed for containerization.
Each cloud service provider has its own implementation of load balancer – most of them allow fine tuning by using service annotations
Enable a readiness probe
A readiness probe informs K8s whether the application is ready to serve traffic or not. You need to enable the readiness probes as they pass traffic to the pod. To do that, you need to have it defined in any of your K8s deployments.
If you don’t have a probe in place, the user will reach the pod but won’t get a healthy server response. That’s because the job of the readiness probe is to signal to Kubernetes when to put a pod behind the load balancer and a service behind the proxy.
Enable a liveness probe
Another key probe you should enable is a liveness probe. It lets Kubernetes know if a pod is healthy enough to continue working or if restarting it is a better idea. It carries out a simple or complex check based on bash commands.
This probe is there to help K8s determine whether load balancing works well or whether some of its components require support. Liveness probes increase availability even if your application contains bugs.
Apply network policy
To protect your K8s deployment, the load balancer must be able to apply security group policies to virtual machines or worker nodes.
In an ideal scenario, you should limit the inbound and outbound traffic to the minimum requirement. What’s the benefit of placing such a limitation? It helps you prevent accidental exposure of unwanted services to the outbound traffic flow.
Kubernetes comes with network security policy functionality capable of serving all resources within deployments. You also need to make sure that your Kubernetes cluster is provisioned with a network plugin that supports network policies.
Enable CPU/Memory requests
That way, the containers will be able to request resources automatically. This helps free up the CPU and memory resources the system needs. Also, enabling these requests lets you define these resources so the pod never runs low in memory. On top of that, you eliminate the risk of CPU or memory taking over all resources on a node and leading to an error or failure.
Optimize Kubernetes beyond load balancers
When dealing with workloads that require high availability, it’s important to spread pods between different availability zones (AZs). This is how you ensure that the application is accessible even if one of the AZs is down. CAST AI supports such scheduling of pods similarly to the K8s scheduler.
Having pods distributed across different availability zones implicates the use of LoadBalancer, which supports distributing traffic between different zones. In most cases, it should be working out of the box, as most clouds have a load balancer that supports distributing traffic between zones. Still, it’s worth double-checking that.
Additionally, apart from utilizing different AZs, CAST AI allows you to split the workloads evenly among different subnets so that all of the subnets are well used. You can find more information about subnet usage calculations here.
Kubernetes cost optimization
Monitor organization-wide and cluster-level resource spending. Automate resource allocation and scale instantly with zero downtime.

Bonus: load balancing in your homelab
Deploying a production-grade Kubernetes cluster and using a proper load balancer is one challenge – but what if you want to learn something more about setting up a K8s cluster? Homelab could be an answer to that question.
Creating a K8s cluster just for fun can be challenging but also rewarding. Setting up proper LB in the home network is also difficult because you are unlikely to have enterprise-grade network equipment in the home.
So, the easiest way to expose your pet project from the home cluster would probably be by using K8s service with the NodePort type. There would be no problem with dynamic IP because you would have nodes with static IPs.
But what if we want to go one step further? And want to use something more similar to a production-grade cluster? For this, you can use a project called Metallb. The project is in beta, but should work fine in a homelab. Metallb has two modes of working L2 for which a home router will be enough. In a nutshell, it means that the machine simply has multiple IP addresses.
Or you can use the more advanced mode called BGP. There you have true load balancing across multiple nodes, but the router needs to have BGP support.
We hope this article helped you get to the bottom of the Kubernetes load balancing options, and that you’re ready to use all the load balancers in your next project.



