
Did you know that Kubernetes clusters typically waste 37% of their assigned cloud resources? Overprovisioning or cloud cost savings are a top-of-mind issue for every team out there. And everything starts with the VM instance types you pick for running your workloads.
Compute resources are often the biggest line items on your cloud bill. Selecting the right VM instance types is a key aspect of cloud resource optimization and in some cases can save you 50% of your overall compute bill (confirmed in this report).
If you have optimized your VM choices already, be sure to check our blog for more cost optimization tips – perhaps spot instances are a good start?
Table of contents:
- Choose an instance type with cloud cost savings in mind
- Consider the pros and cons of different pricing models
- Take advantage of CPU bursting
- Check your storage transfer limitations
- Count in the network bandwidth
It’s so easy to overprovision cloud resources
Let’s say that you need a machine with 4 CPU cores. You can choose from some 40 different options, even in a single cloud scenario where you work with only one cloud provider.
How do you compare all these instances? The sheer scale is just too large for human minds to understand and analyze. AWS alone has over 500 EC2 instance types available!
For example, take a look at the following pricing table from AWS:
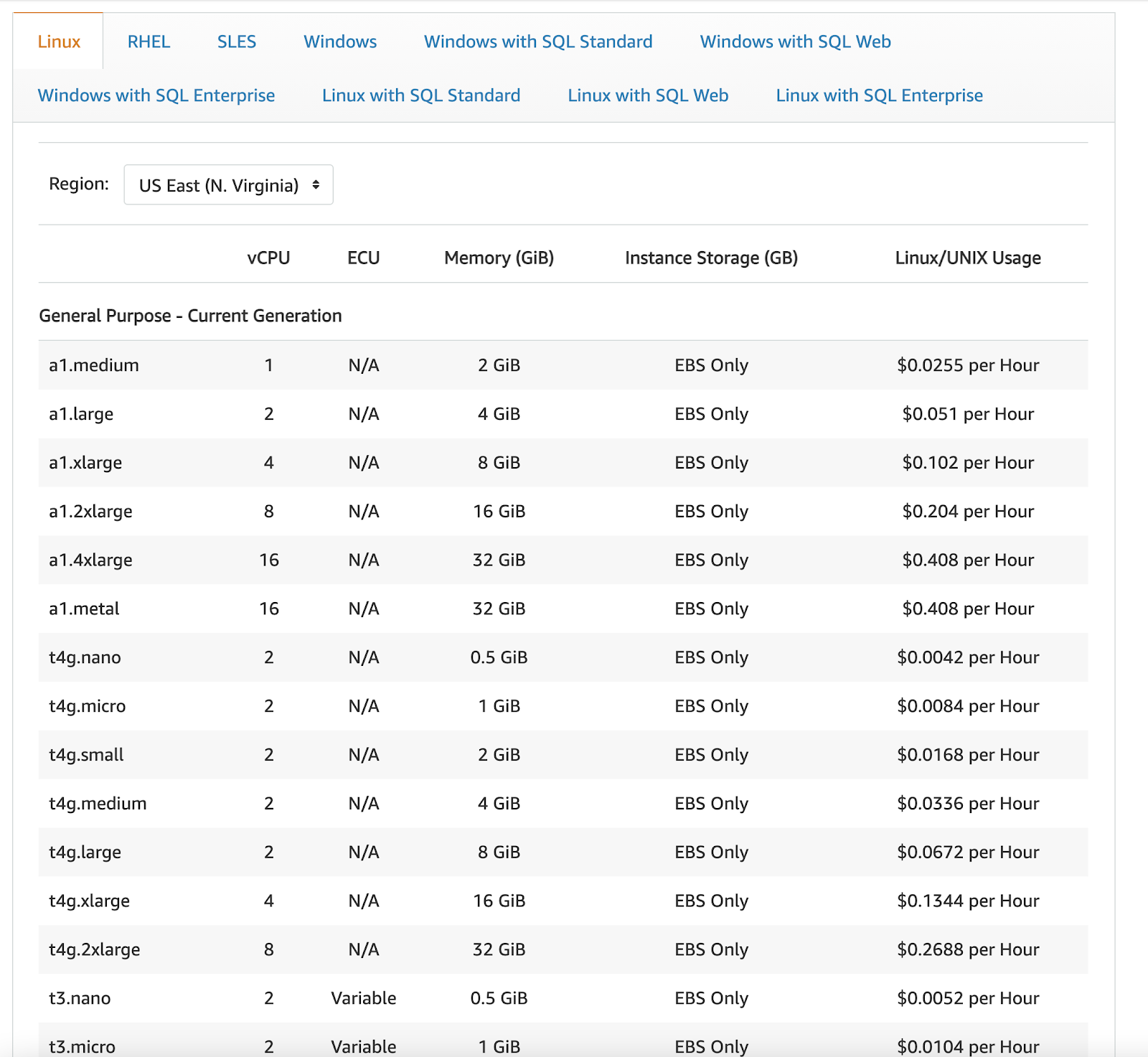
… and this is just a portion of the table, for one region, and one OS type.
We’re talking only about one cloud at this point. Things get exponentially more complicated when you go multi-cloud.
So, let’s say that you pick an instance that costs $0.19 per hour. It seems reasonable on paper, so you modify your Infrastructure as Code (IaC) scripts and deploy.
But when you deploy a compute-heavy application, you soon see that it ends up underutilizing other resources you’re paying for. You’re using only half of the memory allocated per node, underutilizing the network, and not even utilizing the SSDs that may be attached to the instance. This doesn’t help to maximize cloud cost savings at all.
If you took a deeper look into the provider’s offering, you may find another VM instance type that could support your application for a much lower cost. Sure, it gives you less memory and network, but that’s absolutely fine by your application. And it costs much less – only $0.10 an hour.
This scenario isn’t made up – these are the results of a cost/performance test that we carried out on a demo e-commerce application. You’ll find the case study further down this article, so bear with us.
How to choose the right VM instance type in 6 steps
1. Define your minimum requirements
Your workload matters a lot when you’re choosing a VM instance type with cloud cost savings. You should be making a deliberate effort to order only what you need across all compute dimensions including CPU (and type x86 vs ARM, vs. GPU), Memory, SSD, and network connectivity.
While an affordable instance might look tempting, you might suffer performance issues when you start running memory-intensive applications.
Identify the minimum size requirements of your application and make sure that the instance types you select can meet them across all dimensions:
- CPU Count
- CPU Architecture
- Memory
- SSD Storage
- Network
Once you find a set of instance types that fit your application needs, buying a “good enough” instance type might not be the best possible choice. For example, different VMs across different clouds have varying price vs. performance ratios. This means that it’s possible to get better performance for the cloud compute dollar and save more on cloud costs overall.
Next, you select between CPU and GPU-dense instances. Consider this scenario:
If you’re building a machine learning application, you’re probably looking for GPU-dense instance types. They train models much faster than CPUs. Interestingly, the GPU wasn’t initially designed for machine learning – it was designed to display graphics.
In 2007, Nvidia came up with CUDA to help developers with machine learning training for deep learning models. Today, CUDA is widely adopted across the most popular machine learning frameworks. So, training your ML models will be much faster with GPUs.
What about running predictions through your trained models? Can we achieve better price/performance with specialized instance types? CSPs are now introducing new instance types designed for inference – for example, AWS EC2 Inf and In2 instances. According to AWS, EC2 Inf1 instances deliver up to 30% higher throughput and up to 45% lower cost per inference than Amazon EC2 G4 instances.
Unfortunately, the selection matrix gets more complicated.
2. Choose an instance type with cloud cost savings in mind
Cloud providers offer a wide range of instance types optimized to match different use cases. They offer various combinations of CPU, memory, storage, and networking capacity. Each type includes one or more instance sizes, so you can scale your resources to fit your workload’s requirements.
But cloud providers roll out different computers and the chips in those computers come with different performance characteristics.
You might be getting an older-generation processor that’s slightly slower – or a new-generation processor that’s slightly faster. You might choose an instance type that has strong performance characteristics that you don’t actually need, without even knowing it.
Reasoning about this on your own is hard. The only way to verify this is through benchmarking – dropping the same workload on each machine type and checking its performance characteristics.
This is one of the first things that we did at CAST AI when we started. Here are two examples.
Example 1: Unpredictable CPUs within one provider
This chart shows the CPU operations in AWS (Amazon t2-2x large: 8 virtual cores) at different times after several idle CPU periods.
Example 2: Cloud endurance
To understand VM performance better, we created a metric “Endurance Coefficient” and here’s how we calculate it:
- We measure how much work the VM type can do in 12 hours and how variable the CPU performance is.
- For a sustained base load, you’d want as much stability. For a bursty workload (a website that experiences traffic once in a while or an occasional batch job), lower stability is fine.
- You should make an informed decision since sometimes it’s not clear how much stability you’re getting for your money with shared-core, hyperthreaded, overcommitted, between generations, or burstable credit-based VM types.
- In our calculation, instances with stable performance edge close to 100, and ones with random performance are closer to 0 value.
In this example, the DigitalOcean s1_1 machine achieved the endurance coefficient of 0.97107 (97%), while AWS t3_medium_st got only a weirdly shaped 0.43152 (43%) – not that it’s a burstable instance.
Let’s get back to choosing the instance type
AWS, Azure, and Google all have these four instance types:
- General purpose – This instance type has a balanced ratio of CPU to memory, a good fit for general-purpose applications that use these resources in equal proportions such as web servers with low to medium traffic and small to medium databases.
- Compute optimized – Optimized for CPU-intensive workloads, this VM type comes with a high ratio of CPU to memory. It’s a good fit for web servers experiencing medium traffic, batch preprocessing, network appliances, and application servers.
- Memory optimized – This type has a high memory-to-CPU ratio. That’s why it’s a good fit for production workloads like database servers, relational database services, analytics, and larger in-memory caches.
- Storage optimized – Workloads that require heavy read/write operations and low latency are a good fit for this instance type. Thanks to their high disk throughput and IO, such instances work well with Big Data, SQL and NoSQL databases, data warehousing, and large transactional databases.
Each provider also offers instance types for GPU workloads under different names:
AWS
- Accelerated computing – These instances use hardware accelerators (co-processors) to carry out functions like data pattern matching, graphics processing, and floating point number calculations more efficiently than with CPUs. Great for machine learning (ML) and high-performance computing (HPC).
- Inference type – for example, AWS EC2 Inf promises up to 30% higher throughput and 45% lower cost per inference than AWS EC2 G4 instances.
- GPU – Machines recommended for most deep learning purposes.
Azure
- GPU – Powered by Nvidia GPUs, these instances were designed to handle heavy graphic rendering, video editing, compute-intensive workloads, and model training and inferencing (ND) in deep learning.
- High-performance compute – This type offers the fastest and most powerful CPU VMs with underlying hardware optimized for compute- and network-intensive workloads (which includes high-performance computing cluster applications). A great combination with high-throughput network interfaces (RDMA).
Google Cloud Platform
- Accelerator-optimized – Based on the NVIDIA Ampere A100 Tensor Core GPU, these VMs get you up to 16 GPUs in a single VM. Great for demanding workloads like HPC and CUDA-enabled machine learning (ML) training and inference.
Check these links for more info:
A note about ARM-powered VMs
Here’s what you need to know about ARM-based VM instance types: it’s less power-hungry, so cheaper to run and cool – CSPs charge less for this type of processor. But if you’re toying with the idea of using it, you might need to re-architect your delivery pipeline to compile your application for ARM. If you’re running an interpreted stack like Python, Ruby, or NodeJS, your apps will likely just run.
3. Consider the pros and cons of different pricing models
Your next step is picking the right pricing model for your needs. Cloud providers offer the following models:
- On-demand — In this model, you pay for the resources that you use (for example, AWS charges compute capacity by the hour). There are no long-term binding contracts or upfront payments. You can increase or decrease your usage just in time. This flexibility makes on-demand instances great for workloads with fluctuating traffic spikes.
- Reserved Instances (Committed use discounts in Google Cloud Platform) — Reserved Instances allow purchasing capacity upfront in a given availability zone for a much lower price than on-demand instances. In most cases, you commit to a specific instance or family, and can’t change it if your requirements change later. Generally, the larger the upfront payment, the larger the discount. Commitments range from 1 to 3 years.
- Savings Plans (AWS) — In this model, the same discounts as Reserved instances for committing to use a specific amount of compute power (measured in dollars per hour) over the period of one or three years. After committing to a specific amount of usage per hour, all usage up to it is covered by the Savings Plan, and anything extra is billed at the On-demand rate. Unlike Reserved Instances, you don’t commit to specific instance types and configurations (like OS or tenancy), but to consistent usage.
But didn’t you go to the public cloud to avoid CAPEX in the first place? By choosing reserved instances or the AWS savings plan, you’re running the risk of locking yourself in with the cloud vendor and securing resources that might not make sense for you in a year or two. In cloud terms, 3 years is an eternity.
This is an evil practice on the part of CSPs. They lock customers in for a discount and cut them off from alternatives for years to come.
- Spot instances (Preemptible in GCP) — In this pricing model, you bid on spare computing resources. This can bring cloud cost savings up to 90% off the on-demand pricing. The problem with spot instances is that they don’t guarantee availability, which varies depending on current market demand in a given region. Spot instances might make sense if your workload can handle interruptions (for example, if you’ve got stateless application components such as microservices).
- Dedicated host (sole tenant nodes in GCP) — A Dedicated host is a physical server that has an instance capacity fully dedicated to you. It allows using your own licenses to slash costs but still benefit from the resiliency and flexibility of a cloud vendor. It’s also a good fit for companies that need to meet compliance requirements and not share the same hardware with other tenants. Regulated markets that deal with lots of sensitive data often choose dedicated hosts for the perceived security benefits.
Note: Don’t forget about the extra charges. AWS, Azure, and GCP all charge for things like egress traffic, load balancing, block storage, IP addresses, and premium support among other line items. Take them into account when comparing instance pricing and building your cloud budget.
And each item deserves your attention.
Take egress traffic as an example. In a mono-cloud scenario, you’ll have to pay egress costs between different availability zones, which is in most cases $0.01/GB. In a multi-cloud setup, you pay a slightly higher rate, like $0.02 when using direct fiber (for the US/EU).
4. Take advantage of CPU bursting
Take a closer look at each CSP, and you’re bound to see “burstable performance instances.”
These are instances designed to offer teams a baseline level of CPU performance, with the option to burst to a higher level when your workload needs it. They’re a good match for low-latency interactive applications, microservices, small and medium databases, and product prototypes, among others.
Note: The amount of accumulated CPU credits depends on the instance type – larger instances collect more credits per hour. However, there’s also a cutoff to the number of credits you can collect, and larger instance sizes come with a higher cutoff.
Where can you get burstable performance instances?
AWS
- Instance families: T2, T3, T3a, and T4g.
- Restarting an instance in the T2 family = losing all the accrued credits.
- Restarting an instance in T3 and T4 = credits persevere for seven days and then are lost.
- Learn more here.
Azure
- B series VMs of CPU bursting.
- When you redeploy a VM and it moves to another node, you lose the credits.
- If you stop/start a VM while keeping it on the same node, it retains the accumulated credits.
- Learn more here.
GCP
- Shared-core VMs offer bursting capabilities: e2-micro, e2-small, e2-medium.
- CPU bursts are charged by the on-demand price for f1-micro, g1-small, and e2 shared-core machine types.
- Learn more here.
Our research into AWS showed that if you load your instance for 4 hours or more per day, on average, you’re better off with a non-burstable one. But if you run an online store that gets a stream of visitors once in a while, it’s a good fit.
Note: CPU capacity has its limits
We discovered that compute capacity tends to increase linearly during the first four hours. But after that, it becomes much more limited. The amount of available compute reduces almost by 90% until the end of the day.
5. Check your storage transfer limitations
Here’s another thing to consider when maximizing your cloud cost savings: data storage.
- AWS EC2 instances use Elastic Block Store (EBS) to store disk volumes,
- Azure VMs use data disks,
- And GCP has the Google Persistent Disk for block storage.
- You get local ephemeral storage in AWS, Azure, and GCP too.
Every application has unique storage needs. When choosing a VM, make sure that it comes with a storage throughput your application requires.
Also, don’t opt for pricy drive options like premium SSD – unless you expect to employ them to the fullest.
6. Count in the network bandwidth
If you have a massive migration of data or a high volume of traffic, pay attention to the size of the network connection between your instance and the consumers assigned to it. You can find some instances that can bolster 10 or 20 Gbps of transfer speed.
But here’s the caveat: only those instances will support this level of network bandwidth.
Saving on cloud costs – case study
We recently tested the CAST AI approach to cloud cost savings on an open-source e-commerce demo app adapted from Google.
Here’s what we did:
- To get some meaningful costs, we load-tested our application with a high number of concurrent users (~1k).
- We then scaled the pods for each microservice accordingly. This was done on AWS EKS with a statically-scaled deployment.
- We ran the test for a 30-60 minute period to capture the metrics.
- Next, we extrapolated costs over a 30-day period, taking into account assumed traffic seasonality. We generated a likely 30-day usage pattern as part of our load testing scripts.
- The resulting usage experienced spikes every day at around the same time and during several days of the week traffic was somewhat heavier.
This is how we calculated the monthly costs of running our app on the AWS test cluster and compared our solution to see how it helps to increase cloud cost savings.
Note that our demo scenario assumes a fixed number of servers in the original EKS cluster and an instance type of m5.xlarge. The original cluster doesn’t use auto scaling or spot instances.
Originally, we selected the m5.xlarge VM that comes with 4 CPUs, 16 GB of memory and a high throughput Network Interface (~10 GiB). The cost of this instance type on-demand is $0.192/hour.
Then we launched CAST AI and let the magic happen.
Through automated analysis, our optimizer selected an alternative shape: a1.xlarge. This instance type has 4 CPUs and only 8 GB of RAM. The pods deployed per VM could easily fit into 8 GB. The additional 8 GB on our former instance (m5.xlarge) was a pure waste of RAM. We were able to select the a1 (ARM) processor by re-compiling our apps and building new container images.
Our new instance had a reduced network throughput. This wasn’t an issue for our app because we were not network bound. That is, the traffic generated with the available compute resources didn’t max out the bandwidth capacity of the selected instance.
And now comes the best part:
The a1.xlarge instance costs only $0.102/hour. This means that we instantly achieved cloud cost savings of 46% per compute-hour.

Try automated VM instance types selection
Compute is what you go to cloud providers for. It’s often the biggest part of your cloud bill, especially if you do something like machine learning. So if you manage to optimize costs there, you’re on the right track to dramatically reducing your cloud bill.
Luckily, automation is here to help you. Making an informed choice is next to impossible considering the volume of options. Instead of betting your favorite instance types, let an automation engine like CAST AI analyze your workload requirements and pick the best machines for you.
You can check which VM instance types are the best match for your workload by running a free Savings Report.



