
The number of open-source and commercial LLMs for generative AI is growing fast. And each comes with multiple versions. Just take a look at the pricing page for OpenAI’s LLM models – it’s 10 pages long, which means you’re looking at at least 20 different models for different use cases with different pricing models.
It’s no wonder that Dev/ML/AI Ops teams are unsure which model best fits their needs (or have time to analyze all the available models). On top of that, the cost of running these resource-intensive models is a hurdle for big and small organizations.
LLM Cost: Why Is It So Hard To Control?
Complexity of the LLM Market
Some teams may not realize that using the default LLM or relying on a single provider might not be the best choice for all of their use cases. As a result, they often use more resource-intensive and expensive models than necessary.
They miss out on more efficient, cost-effective solutions without exploring other options or tailoring models to specific needs. This can lead to unnecessary spending and inefficient resource use, as they stick with high-cost models that aren’t optimized for the full range of tasks within the organization.
Lack of LLM Cost Visibility
MLOps or DevOps teams responsible for building and maintaining infrastructure for generative AI solutions often lack the tools and visibility needed to monitor and manage LLM costs effectively.
While they may be skilled in deploying and maintaining AI models, they’re often left without reporting tools that provide real-time insights into how much each model costs in terms of compute resources, data usage, or API calls.
This lack of transparency makes tracking and optimizing expenses difficult, leading to potential budget overruns or inefficiencies. Without clear visibility into LLM usage patterns, teams can’t make informed decisions about cost-saving measures or identify areas where optimization could reduce expenses.
Cloud Infrastructure Is Not LLM-Friendly
Engineers can choose from hundreds of different compute instances, making it nearly impossible for humans to select the best option – especially when running generative AI workloads on Kubernetes.
The sheer number of choices, each with different performance, pricing, and configurations, creates a complex decision-making process.
Without automation or intelligent tools to guide these decisions, engineers can struggle to find the most efficient and cost-effective instance for their specific workloads, often leading to suboptimal choices that drive up costs and reduce performance.
What Is The Solution?
We are experiencing an unprecedented timeline in AI innovation, with weekly and monthly announcements of new models and architectures. With so many variables involved – from choosing the right model and compute instance to optimizing usage patterns – managing LLM costs manually is inefficient and prone to error. What is the alternative?
Introducing Kimchi
Kimchi intelligently routes queries to the most optimal and cost-effective LLM for each task while leveraging Cast AI’s proven Kubernetes infrastructure optimization capabilities.
With features such as a comprehensive cost monitoring dashboard, automatic selection of optimal LLMs (both OSS and commercial), and zero additional configuration, Kimchi significantly reduces costs and operational overhead – making it easier than ever for businesses to integrate AI into their applications at a fraction of the cost.
How Does Kimchi Work?
Cost Monitoring For LLMs
The cost monitoring tool offers a comprehensive report comparing the expenses of using the default LLM with the potential savings customers can achieve. It features a detailed cost monitoring dashboard that aggregates data from various LLM providers, providing valuable insights into spending patterns.
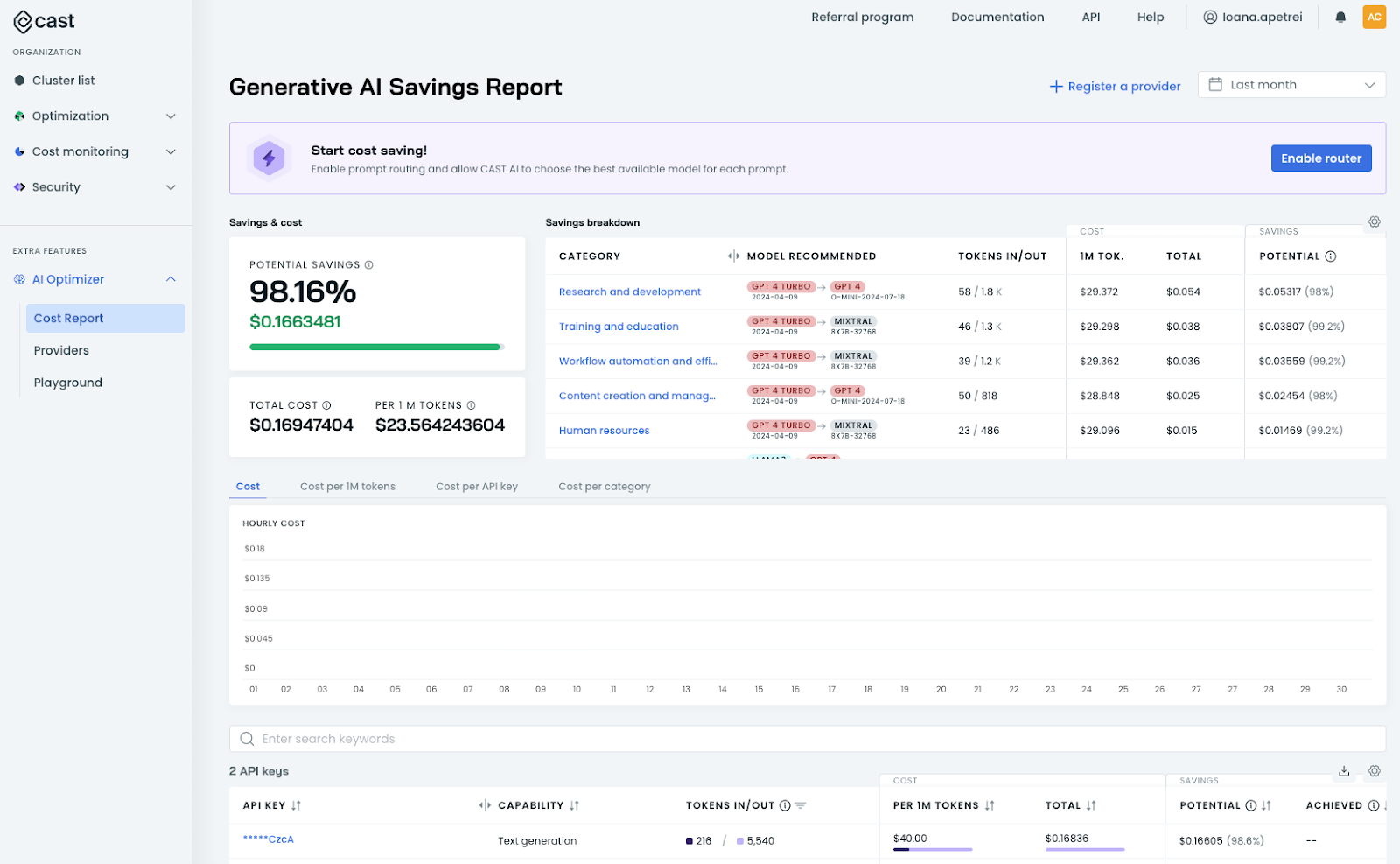
Additionally, customers can leverage the Cast AI playground to compare different LLMs and establish benchmarks, enabling them to identify the ideal configuration tailored to their specific needs. This empowers organizations to make more informed decisions and helps optimize their LLM usage for maximum efficiency and cost-effectiveness.
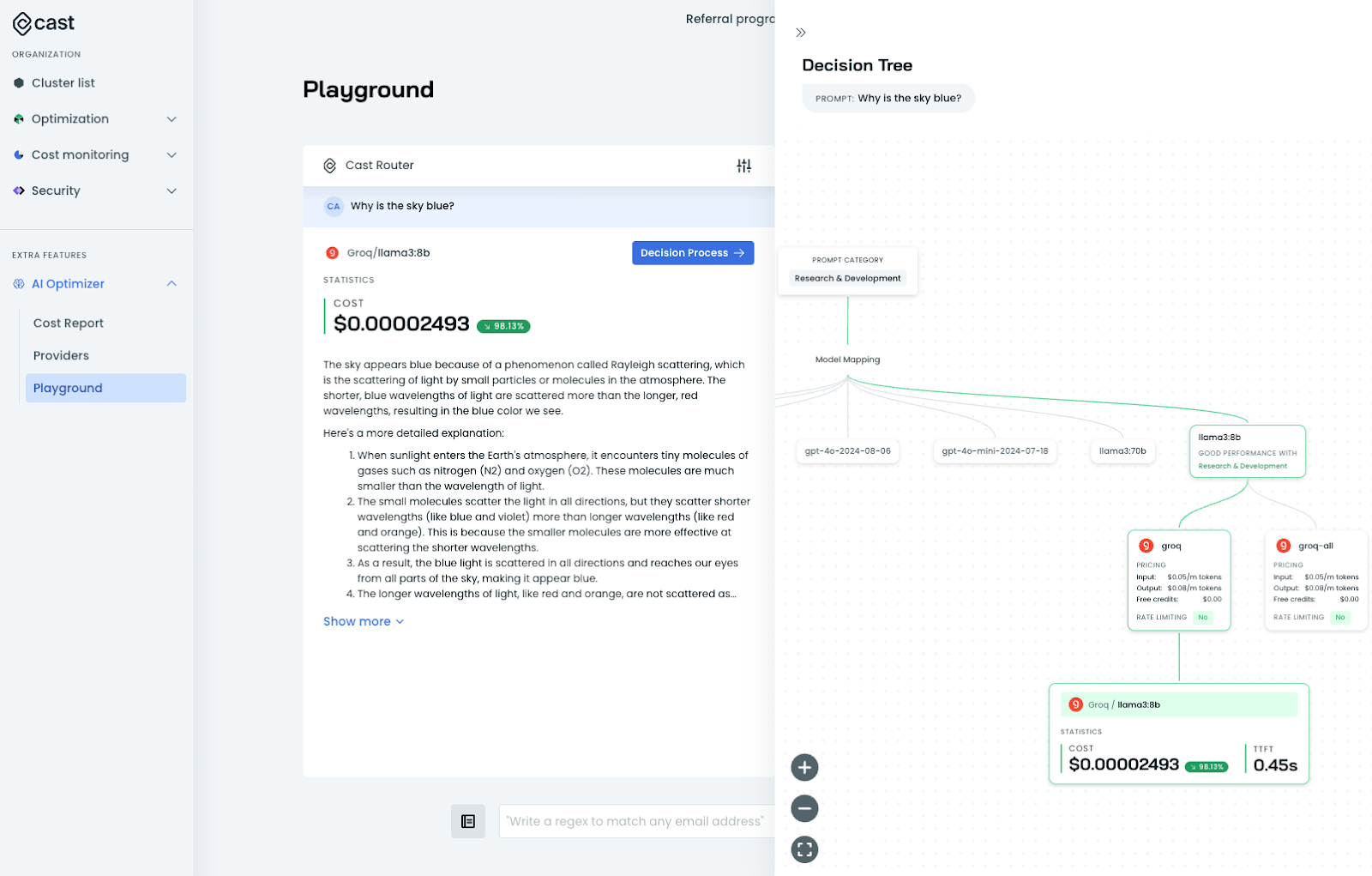
Automated LLM Cost Optimization
The LLM proxy intelligently selects the most optimal LLM model for user queries, ensuring that organizations get the best performance at the lowest cost. This approach delivers maximum savings by choosing and executing an optimized LLM with lower inference expenses.
Running LLMs on Cost-Optimized Infrastructure
Hugging Face, the leading open-source platform for AI builders, sees the value in automation and uses it to reduce the cost of deploying Large Language Models (LLMs) in the cloud. Hugging Face and Cast AI have teamed up to automatically run Hugging Face customer LLMs on Kubernetes clusters optimized by Cast AI’s automation platform.
Our platform leverages advanced machine learning algorithms to analyze and optimize clusters in real time, helping reduce cloud costs while improving performance and reliability. The platform includes a Workload Optimization designed for CPU- and GPU-intensive workloads.
Understand And Optimize Your LLM Costs Starting Now
Book a personalized demo of Kimchi to learn how much you could save on LLMs.
LLM optimization for AIOps
Test and deploy the most optimal LLM model for performance, cost and security.




