
Kubernetes workloads are typically dynamic, with Pods created, destroyed, or rescheduled across nodes due to scaling operations or hardware failure. This makes maintaining stable network identities and seamless communication between components challenging. This is where Kubernetes services come in.
A Kubernetes service is an object designed to abstract a set of endpoints (typically Pods) and provide a way to access those over the network.
Services abstract away the complexities of discovery and load balancing, allowing developers to focus on application logic rather than infrastructure.
In this article, we will explore the basics of services and the different types and use cases provided by Kubernetes out of the box.
What are Kubernetes services?
Let’s start with the basics: what is a Kubernetes service? In a nutshell, a service is a tool for implementing the following scenario:
“My application X wants to access application Y in a consistent way over the network.”
Imagine that we have a pizza-baking application. It’s deployed in three Pods and can scale horizontally up or down based on traffic (for example, on a Friday night). We also have a pizza delivery app that needs to ask the baking application for new pizzas as orders come.
Without a service, our delivery application has to keep track of the three Pods, detect and remove dead Pods from the list, add new Pods during scale-up events, and choose which Pod to send traffic to for every request.
We have to potentially do this for every network dependency, and we can see complexity rising quickly.
Instead, we can abstract the pizza-baking application via a service using the manifest below:
apiVersion: v1
kind: Service
metadata:
name: pizza-baker-svc
namespace: default
spec:
type: ClusterIP
selector:
app.kubernetes.io/name: pizza-baker
ports:
- protocol: TCP
port: 80
targetPort: 9376Let’s break this down:
- We define an object of kind=Service
- We give our service a name=pizza-baker-svc.
- We define how to find the pizza baker application via the selector field. In this example, we assume that means all pods with the label
app.kubernetes.io/name=pizza-baker. - We map the service and target ports. This means traffic from port 80 towards the service will be directed to port 9376 on the Pod.
By applying this manifest, we create the service. Behind the scenes, Kubernetes starts doing a whole bunch of work:
- The service will be assigned a private IP (e.g.,
10.96.117.59). - Network routes within the cluster are updated so traffic to the IP is routed to actual pods.
- In addition to routing, traffic is balanced between the pods.
- DNS entries for
pizza-baker-svc,pizza-baker-svc.defaultandpizza-baker-svc.default.svc.cluster.localare created, enabling other applications to use the name instead of IP. - A background process keeps everything in sync as the pods of
pizza-bakercome and go.
We will cover the magic in detail in a future blog post. The important note is that our pizza-delivery application now has an easy way to access the pizza-baker pods—via our service’s IP or DNS name—without any heavy lifting to keep that information in check.
We have essentially decoupled the two applications, making developer and operations’ lives easier!
Types of Kubernetes services
We just saw an example that uses the ClusterIP service type. However, Kubernetes provides four main categories of services:
- ExternalName,
- LoadBalancer,
- NodePort,
- ClusterIP (with a subtype of Headless service)
ClusterIP
We already saw ClusterIP, the default Kubernetes Service type. The diagram below roughly shows the flow. Traffic is routed towards the service IP, which then gets rerouted via proxying to an actual pod IP.
As we can see, the service is a decoupling mechanism between the two applications, and pizza delivery is unaware of the actual pizza-baker Pod state.
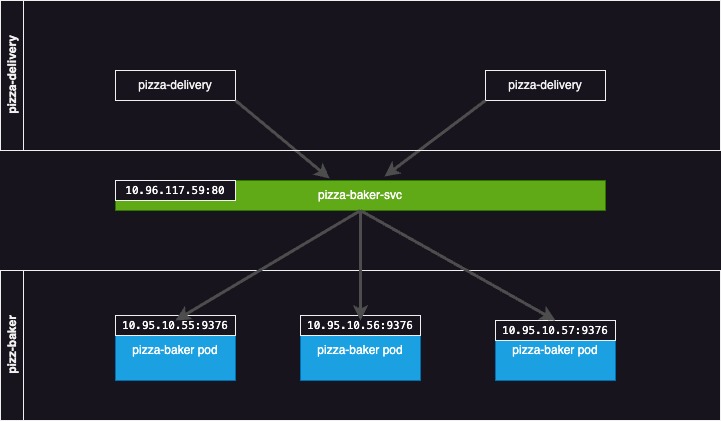
This is the standard go-to approach for internal service communication in Kubernetes and the basis for other types, which we will see below.
NodePort
The NodePort type of service extends ClusterIPs by opening a port on every node in the cluster and proxying traffic from that port to the service.
Here is a sample manifest for a NodePort version of our pizza-baker service:
apiVersion: v1
kind: Service
metadata:
name: pizza-baker-svc
namespace: default
spec:
type: NodePort
selector:
app.kubernetes.io/name: pizza-baker
ports:
- protocol: TCP
port: 80
targetPort: 9376
nodePort: 30007
The field nodePort defines which port is used to proxy traffic. Kubernetes only allows specific port ranges, so not everything is available. A randomly available port is assigned instead if a port is not specified.
Behind the scenes, a ClusterIP is still reserved. However, traffic can now use nodes as an initial proxy, as shown in the diagram below.
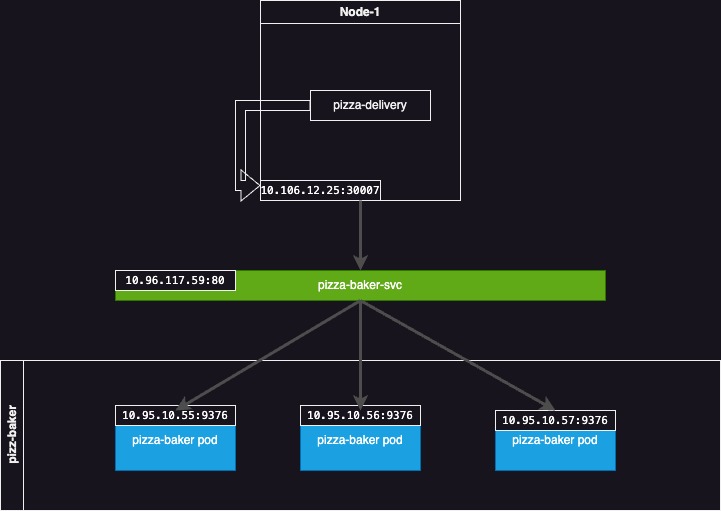
The pizza delivery application calls its own node using <nodeIP:nodePort> (10.106.12.25:30007). Note that every other cluster node’s IP can be used as well.
This traffic is then captured via proxy “magic” and sent to the backing ClusterIP service. Then, the same mechanism used previously to route traffic to an actual pod kicks in, and the final destination is reached.
One important consideration is that if nodes have public IPs, this service can also expose Pods to external traffic as the routing works regardless of source.
Sometimes, this is not obvious and risks exposing services that should be internal by mistake. It could be used to access internal cluster services for debugging or testing scenarios. For production usage, a LoadBalancer service is usually required.
LoadBalancer
The LoadBalancer service type exposes applications from the cluster to the outside world by using provider-specific load balancer implementations.
When a service like this is created, a Kubernetes control plane controller will provision the necessary cloud resources and link them to a service in the cluster (by default, a NodePort service type).
Ingress traffic will then hit the load balancer and be routed to the application accordingly, as per the diagram below.
To follow our example from above, we assume that the pizza delivery application is a third-party client that will talk to our pizza baker inside the cluster, and we need a way to enable this communication.
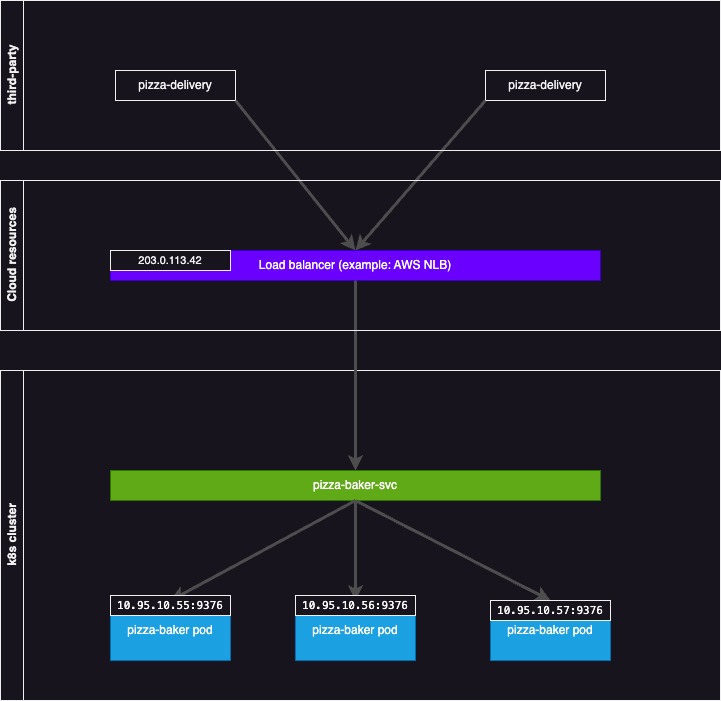
If we see the manifest for a load balancer, it looks deceptively similar to a ClusterIP service:
apiVersion: v1
kind: Service
metadata:
name: pizza-baker-svc
namespace: default
spec:
type: LoadBalancer
selector:
app.kubernetes.io/name: pizza-baker
ports:
- protocol: TCP
port: 80
targetPort: 9376
However, the reality is quite different.
The service now creates additional cloud resources (for example, a Classic Load Balancer for AWS), which incur extra cost and complexity and might need further clean up.
In addition, configuring the load balancer itself is challenging (just see how many annotations the AWS version has). It’s often insufficient for complex scenarios.
That is why, over time, the Ingress object was introduced to handle specifically inbound traffic with more control over the cluster operator.
Still, a LoadBalancer type service is an easy way to get started and expose an application to the world before moving into advanced territory.
ExternalName
So far, we have seen various ways to expose an application running inside the cluster to other applications or the outside world.
The ExternalName service type turns this around and allows us to refer to an application outside the cluster just as we do inside the cluster.
Let’s assume another company operates the pizza-baking application now, and only delivery is in our scope. Here is a sample manifest for our pizza-baker external service:
apiVersion: v1
kind: Service
metadata:
name: pizza-baker-svc
namespace: default
spec:
type: ExternalName
externalName: pizza-baker.example.com
The ExternalName field tells Kubernetes what the real DNS entry of which our service will be an alias is.
After deployment, a CNAME record will be returned when resolving the service DNS name, pointing clients of the pizza-baker-svc to the correct location.
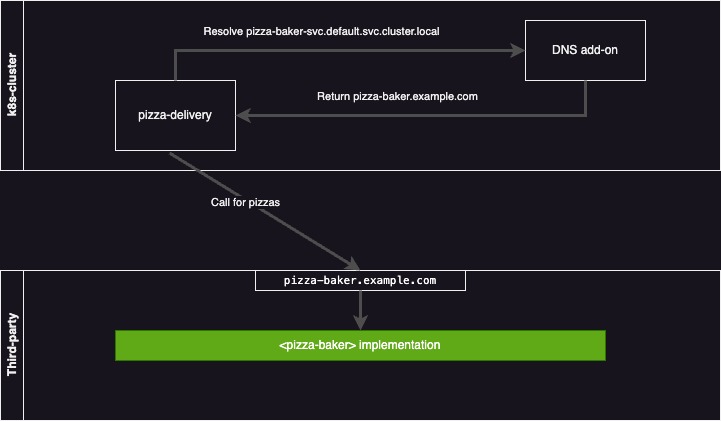
This approach allows us to define a stable DNS name for the external dependency, simplifying configuration.
The pizza-delivery application can use different instances of pizza-baker (e.g., for dev/production environments). Still, it can be assumed it will always be available under `pizza-baker-svc.default.svc.cluster.local`.
It’s important to know that ExternalName services work on the DNS level, so unlike ClusterIP or NodePorts, there is load-balancing magic – that must be handled on the receiving side.
Summary of Kubernetes service types
| Service Type | Definition | Appropriate for | Limitations |
| ClusterIP | The standard service type. The service is exposed via a virtual IP internal to the cluster. | Internal cluster communication | Not externally accessible |
| Headless | Special ClusterIP service where `spec.clusterIP` is set to `None`. It doesn’t allocate a virtual IP, but instead, it returns the IPs of the associated pods via DNS directly | Stateful applications where clients need to access specific pods or know all Pod IPs (e.g., a Kafka cluster, session-aware connections) | No load balancing or proxying by Kubernetes |
| NodePort | Every Node’s IP exposes the service using a static port. It’s reachable by a call to [NodeIP]:[NodePort] (including externally if NodeIP is a public IP address) Kubernetes generates a ClusterIP service and a NodePort service, to which the NodePort service will route automatically | Testing or debugging without setting up a full Load balancer | Dependent on stable node IPs. Can only use specific port ranges. Must ensure no port collisions between services |
| LoadBalancer | Creates an external load balancer (typically through a cloud provider) Usually, load balancers are used to expose the service to the outside world. Kubernetes creates a NodePort and ClusterIP service when you create a LoadBalancer service by default | Exposing services to the internet | It depends on cloud provider implementation otherwise, an Ingress might be needed. |
| ExternalName | ExternalName gives an external service an alias so that it can be addressed as part of the cluster network without creating a proxy or load balancer | Integrating with services outside the cluster, for example, legacy or cloud-hosted databases | No load balancing or service discovery |
Best practices for using Kubernetes services
1. Choose the correct service type
We have already touched on this with the comparison above, but it is important to be mindful when picking the service type.
For example, if a service only receives internal traffic, there is no reason to pay the additional overhead of NodePort or LoadBalancer services. Starting with a service type suited for the use case ensures we don’t overengineer and makes maintenance easier.
2. Be careful when exposing services to the internet
First, be mindful of what should be accessible publicly. Use internal-only ClusterIP services to avoid unwanted exposure, which could become an attack vector.
Second, LoadBalancer should be the preferred service type for such scenarios due to its increased flexibility, feature set, and security (compared to NodePort, which requires public nodes).
3. Implement traffic monitoring
It is important to constantly monitor the traffic and health of the applications behind a service, whether they’re working or not. Using tools like Grafana Kubernetes Dashboard or Prometheus is a must to expose services and ensure they work as expected.
4. Organize services and maintain them as if they are part of the application
As the system grows, so does the complexity of the infrastructure. Ideally, service objects should live together in the same namespace as the application and be managed in tandem. This can be done via a declarative approach with tools like Argo, Helm, or others.
5. Grow up when the time is right
At a certain point, the requirements for the application might become too complex to support via the existing service object functionality.
Instead of trying to shoehorn the solution, consider alternatives like Ingress, Service Mesh, or Gateway APIs.
On the other hand, avoid picking a complex solution too early to avoid unnecessary complexity. Start simple, but be ready to move on when simple is no longer good enough.
We hope this guide illuminates Kubernetes services and best practices, helping you implement them efficiently and securely.
Kubernetes cost optimization
Monitor organization-wide and cluster-level resource spending. Automate resource allocation and scale instantly with zero downtime.




