
You’ve probably heard about automated cloud cost optimization – but what about autonomous cloud cost optimization?
How does this type of optimization actually work? What mechanisms does it use to reduce cloud bills?
Keep on reading to find out.
What is autonomous cloud cost optimization?
Autonomous optimization means that all the optimization tasks are triggered without any active involvement from the DevOps or cloud engineer. But it’s more than automation.
An autonomous solution connects multiple areas of automation together to work in one smooth flow:
- Automated analysis of the cloud resources that identifies areas for optimization,
- Getting you to the optimized state automatically,
- Keeping the optimized state under changing conditions automatically, without involving engineers in proactively managing the infrastructure.
A platform should do all three things to be considered autonomous.
Here’s how an autonomous Kubernetes platform works
Cast AI is a fully autonomous cloud cost optimization platform that supports Kubernetes clusters running on AWS, Google Cloud Platform, and Microsoft Azure Cloud. Here’s a step by step guide to how it optimizes Kubernetes clusters.
Step 1: Automated analysis
To find out how much we could save through the Cluster Analyzer, we need to connect our cluster to Cast AI. So, we create a free account on https://cast.ai and select the Connect your cluster option. To connect the cluster, we need to run a small script in our AWS, GCP, or Azure terminal.
How secure is connecting a cluster to Cast AI?
To deliver meaningful results to you, Cast AI needs minimal cluster access. The platform was created by security specialists and has achieved both SOC 2 Type II and ISO27001 certifications so it follows the principle of least privilege.
The read-only agent launched when you run a script we provide in your terminal cannot change any cluster configuration or access sensitive data. The agent code is open-source and you can see it in our GitHub repository.
- To learn more about how the agent works, take a look here: How does the read-only Cast AI agent work and what data can it read?
- For more on security features, check out this guide to security and privacy in Cast AI
The Savings Report shows what the Cast AI engine would do if we put it in charge of managing our nodes.
This is what the report looks like – note the contrast between the ‘Current Cluster’ and the ‘Optimized Cluster’ at the bottom:
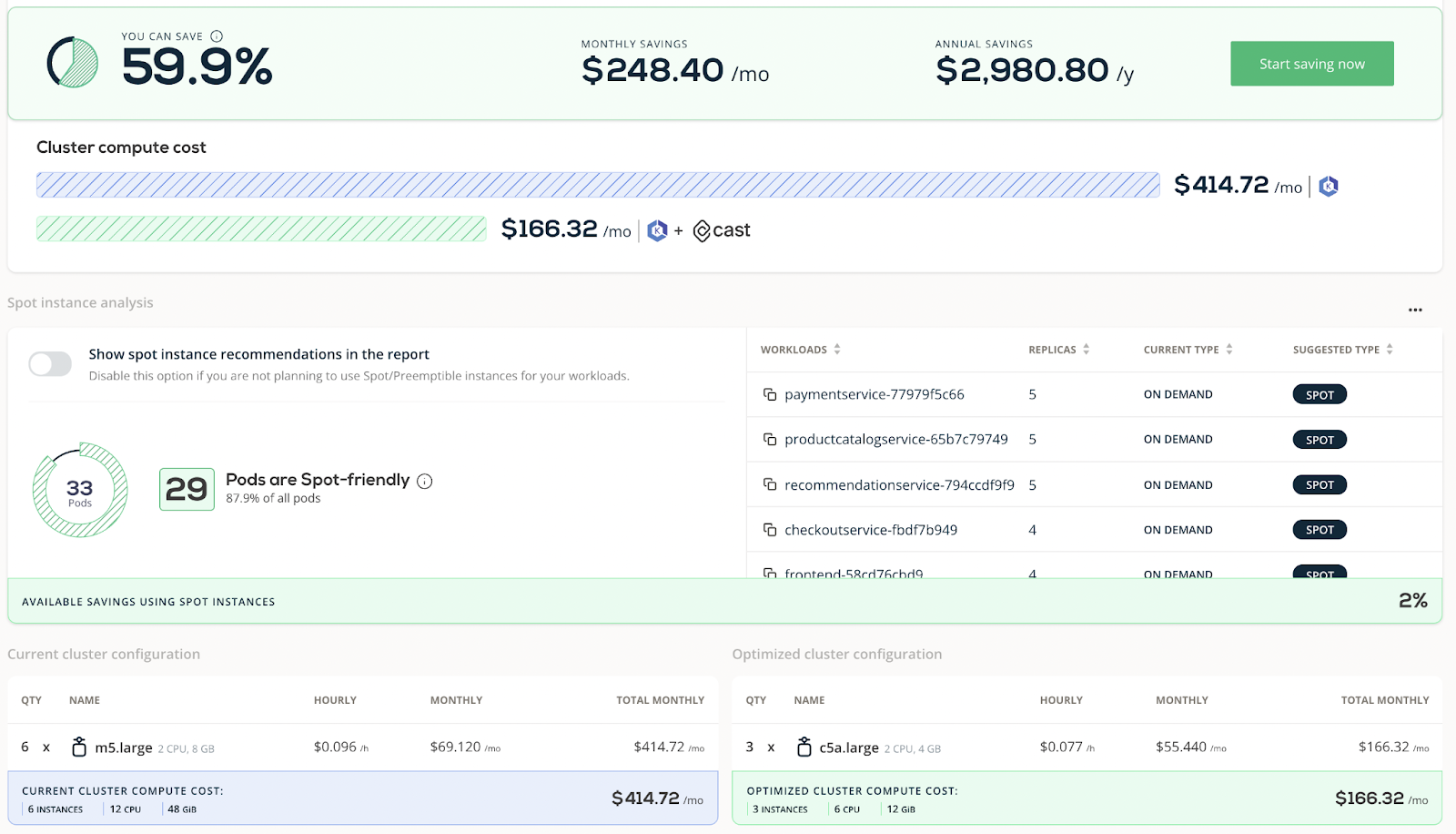
In this example, the platform shows that we’re overprovisioning our cluster. We can see how three virtual machines (nodes) could do the exact same jobs as the six machines we’re using – for a fraction of the cost!
At this point, we can choose between two options:
- Turn autonomous optimization on – the platform will then rebalance our cluster to achieve savings and allow for continued optimization around the clock, finding the best opportunities for getting the performance we need for 40% of the price (or less).
- Change our setup manually to what Cast AI suggested – doing that also means that we’d have to run the reports and do all the required actions manually on a regular basis. Not all of the optimizations can be implemented manually with a similar level of efficiency (for example, autoscaling or managing spot instances).
Step 2: Reaching the ideal state with Instant Rebalancing
Cast AI uses the cluster Instant Rebalancing feature to achieve the optimal configuration in a few minutes.
In our example, six nodes were reduced to three nodes with zero trade-offs on performance. The platform achieved that by seamlessly moving our workloads from the existing 6 nodes to 3 nodes achieving greater resource utilization. The cluster now costs $168.63 per month, instead of the initial $420.48 (59.9% savings!).
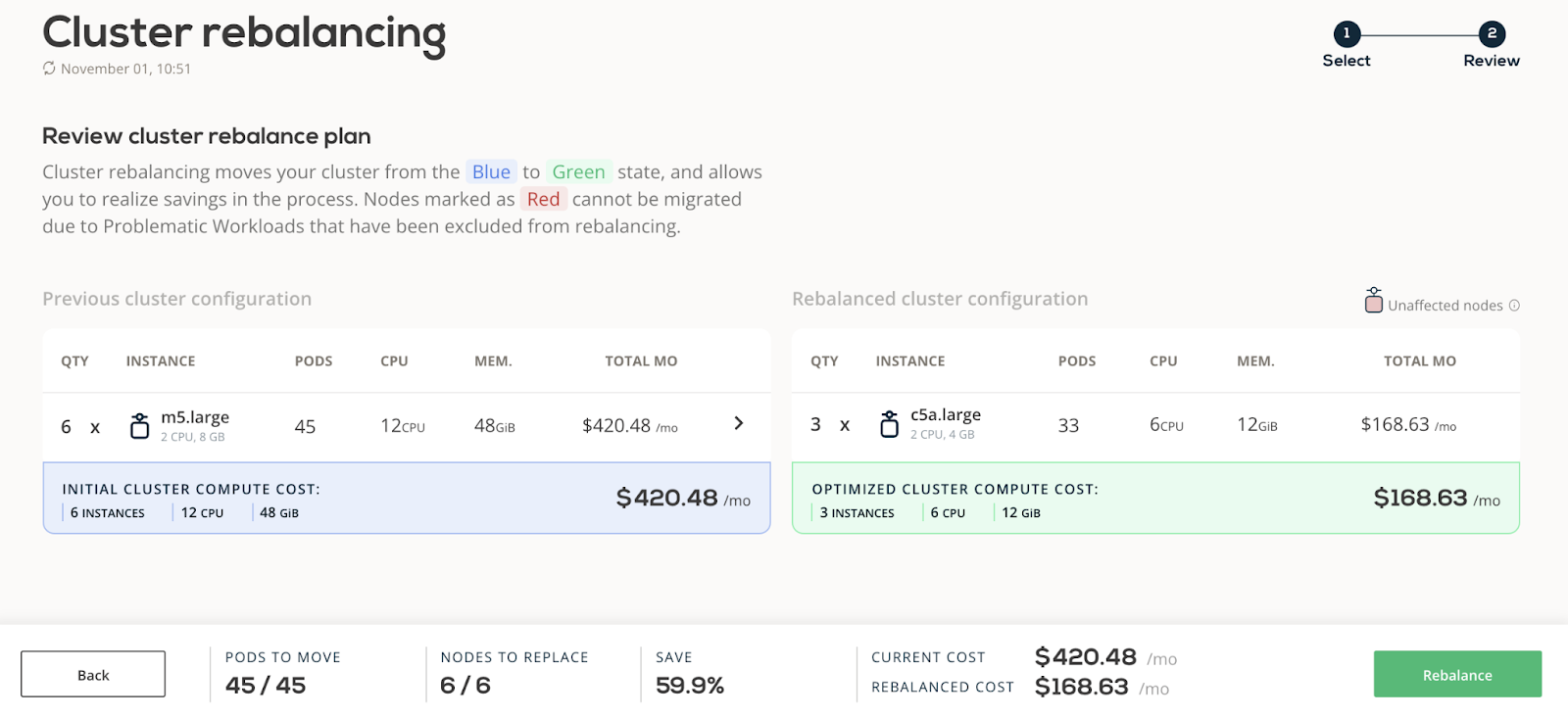
Let’s take a look at our cluster before and after rebalancing
Before rebalancing: The cluster has six nodes and costs $420.48 per month.
After rebalancing: The cluster has three nodes that ensure the exact same level of performance as before, only for $168.63 per month.

Once the process is completed, we get a report summarizing what has been done:
Cluster Rebalancing with spot instances
If we decide to use spot instances in our cluster, we can enable the corresponding policy in the Cast AI console, so the engine includes spot instances in its search for the most optimal compute resources.
Spot instances are virtual machines sitting idle and cloud service providers offer them for a greatly discounted price – even 90% off the on-demand cost. The only catch is that the provider can reclaim these resources at any time. Naturally, an autonomous platform first checks if and how many of the workloads are spot-friendly.
In our example, Cast AI discovered that 29 pods are spot-friendly. This means that the workloads running on those pods will be able to handle the interruption gracefully. By allowing the platform to use spot instances, we drove the monthly bill down to $100.08 per month, a further ~40% decrease from our optimized setup.

Step 3: Staying optimized automatically
Once it achieves an optimized state of the cluster, Cast AI engages Day 2 Ops strategies that continuously optimize the cluster in a feedback loop.
Cast AI analyzes the configuration in real time and makes predictions about cluster requirements. It rightsizes our cluster to the right number, type, and size of compute resources.
For spot instances, Cast AI includes the Spot Fallback feature that guarantees capacity by temporarily moving workloads to other nodes until there are new spot instances available.
Every time a scale-up event occurs (for example, your application gets lots of traffic because of an ad), Cast AI chooses the best resources for the job. This includes on-demand instances and spot instances that work with any Reserved Instances or Savings Plans that we might have at the moment.
The platform uses a number of tactics to ensure continuous optimization of the cluster:
- Smart selection of the most efficient virtual machines for the job,
- Automatic selection of spot instances for any spot-friendly pods,
- Constant checks for pods that could be reshuffled to empty and delete nodes,
- Autoscaling resources to meet the application’s demands,
- Seamless transitioning of your legacy nodes to optimized ones.



