
9 out of 10 startups fail to cross the chasm to the late majority.
A lot of companies have good ideas, and some even find their product-market fit. But those that actually cross the chasm are usually the ones that can DELIVER FAST.
The fate of your company depends on your product team’s ability to deliver and execute fast.
Today, it’s almost impossible to objectively measure how efficient your engineering team is. And we all know that if you can’t measure it, you can’t improve it. You’ll be stumbling in the dark.
But don’t lose all hope. There are still some metrics left that help to tell whether your team is high-performing or still needs some improvement.
Lines of code, velocity, and hours worked are bad KPIs
The software engineering industry is over half a century old. Over that time, teams have been using various vanity metrics to tell whether they’re productive or not.
1. Lines of code
This is a really bad metric because lines of code are a liability. Bigger codebases are harder to read or maintain. I hope nobody counts them anymore to show how successful their team is. One should promote line removal, and pull requests like this should be celebrated:

2. Velocity
Product managers love to count Scrum sprint velocity points as a team efficiency metric. But when you start doing that, the points may start to inflate. You wanted points; you’ll get points. Most likely, you’re not in the business to produce more imaginary points. Depending on what your setup is and how you organize/promote work, this might encourage technical debt.
3. Number of hours worked / How busy people look
In this approach, you count the number of hours people work per week. This might work for physical labor, where longer hours bring you somewhat better results. But the same doesn’t hold true for mental labors.
In software engineering, you’re bound to see diminishing returns on working long hours, and after a certain threshold, developers start producing negative work – introducing bugs. After all, teams should be focusing on delivering value to the user, not working over dull long hours. Or pretending to work long hours – or worse, taking pride in how many hours they’ve worked!
These metrics aren’t helpful at all for measuring team efficiency. What’s more, they’re harmful to the team because they encourage undesirable behaviors.
What metrics should you measure then?

Today as ever, what you’re building is more important than how fast you’re building it. The outcome (user value created) is much more important than the output (features produced).
It doesn’t matter how fast you deliver a product/feature if nobody needs it. Some ⅔ to ¾ of ideas in a backlog are bad; they won’t bring the desired effect. Agile gives you many tools to validate ideas as cheaply and as fast as possible, ideally without writing a single line of code.
Engineering teams contribute a lot to product management in a healthy environment with ideas, suggestions on what to work on next. But having said that, the engineering team’s main capability – the reason why team members were hired – is to develop features. And do it on time.
Let’s put product management metrics aside and focus on engineering excellence and the team’s ability to execute fast.
Based on the stories we’ve heard from successful companies like Google, these metrics seem to matter a lot:
1. Developer engagement / satisfaction / burnout
2. Team culture
But how do you actually measure them? Most of the time, the only way is by employee surveys.
But don’t count on surveys to give you objective data. Depending on what has been happening in the company over the last few days, these surveys might bring different results.
Let’s say that you decided to trust the survey results. Even if you get some numbers, you’ll have no idea what to do next to improve those measures.
Should you get a kombucha tap or an Xbox to improve team satisfaction? Is that really going to help your team deliver faster and with better quality?
Survey results can’t tell you that because they aren’t prescriptive.
Here’s another metric that successful companies measure:
3. Time to market
This is a good one. It’s down-to-earth and clear. But it comes with one problem – it’s a long-term metric. It takes a lot of time to get feedback on how you’re doing. And once you get that feedback, it still doesn’t tell you what you should be improving, as there might be several teams involved in the delivery.
So, where do we go from there? What should CTOs and team leads measure instead?
Let’s start at the beginning.
What do high-performing teams have in common?

High-performing teams are highly motivated. But what drives the motivation among software engineers? Here are three key ingredients.
1. Autonomy – desire to be self-directed
We don’t want to have total chaos and anarchy in the team. But controlled autonomy can bring amazing results in terms of team motivation.
Here are a few tips to increasing autonomy in your team:
- Foster psychological safety – This can be measured by the number of minutes each teammate speaks for during meetings. If that number is equal between team members, it’s a good sign. It means that you managed to create a safe space where people can express their ideas and challenge the assumptions of the management.
- Build a generative culture (the bottom-up approach) – So, you hired some smart people. Let them contribute to the product or suggest new features and ways of working. Don’t dictate how work should be done following the top-to-bottom approach. Listen and let people decide how to work.
- Let people pick their tools – When forced to work with tools they hate, developers easily lose their motivation. Allow people to work with tools they love. And if you have several teams, make sure to reach a consensus that helps to avoid ending up with a zoo of tools for the same job.
- Allow for cross-team independence – If a product team wants to move fast, it might get hindered by the organization’s bureaucratic process. So, the team needs to be autonomous to make significant changes to the product without having to get a sign-off from the rest of the company.
2. Mastery – urge to get better
The desire to get better at their job is an innate behavior of every professional.
The 2020 Developer Survey from Stack Overflow survey showed that 41.4% of developers consider professional growth as a key job factor.
If your product is as interesting and challenging as CAST AI, you don’t have to think twice about this. Your team will get to learn many new things and expand their skill sets naturally.
But what if your product has been in development for some years now and it doesn’t present such a challenge to your team?
Here are two things you can do.
Encourage side projects
Allow developers to dedicate 10% of their time to side projects where they can try their hand at new technologies, play around with some wacky ideas, test things, and grow as professionals.
As a side effect, you might get unexpected innovation – like a feature appearing out of the blue or a new business opportunity.
Bring in peer review
Peer reviews are a must tool for quality, but they are also an awesome tool that drives professional growth. They offer an opportunity for team members to share their feedback and help each other grow professionally.
Note that before the team achieves that tribal stage of “We’re so great together,” each team member should individually feel great. Make sure that every person on your team is growing and that nobody lags behind due to a lack of motivation.
3. Purpose – being part of something bigger
Share your business context and product vision with the team. Do it often.
Don’t only tell it as a manager would tell it to employees. Let the product team give their feedback – criticize your ideas and be a force molding the company vision, not just contributing to it.
At CAST AI, we use OKRs to make sure that all our work is aligned, meaningful, and visible. That way, it’s clear how even the smallest tasks contribute to the company goal.
____
These three motivations give us a good overview of what high-performing teams do and what we should be doing. But still, it’s not something we can measure.
Fortunately, you can find some metrics that work here.
4 super metrics that actually mean something
I’m talking about these 4 metrics:
- Deployment lead time
- Deployment frequency
- Mean Time To Recovery (MTTR)
- Change fail percentage
Some of you might be thinking this right now:
Wait, why should I use a bunch of DevOps metrics?
To answer this question, let’s go back to what Uncle Bob said once:
“The only way to go fast is to go well!”
Robert Martin
Here’s a graph that explains this:
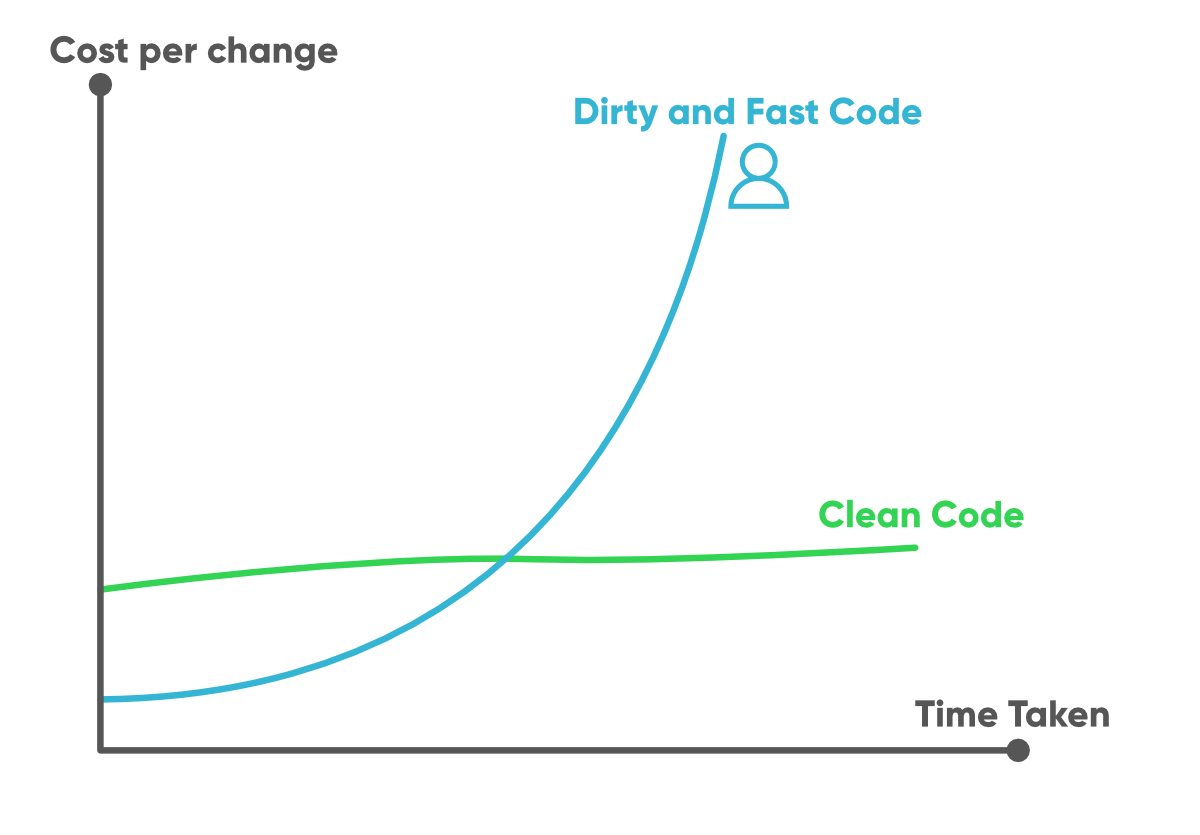
Teams that focus exclusively on feature development – getting features as quickly out of the gate as possible – neglect technical debt or spend zero time on operational excellence. At one point or another, their delivery starts slowing down, the complexity increases, and they’re not able to ship fast anymore.
Teams that pay the technical debt and have operations excellence as a goal from the beginning continue to be effective over time as their complexity grows.
Let’s now dive into the details of these metrics. I’ll show you some best practices and lessons learned from our team at CAST AI.

1. Time from commit to production: Under 60 minutes
This one measures how much time passes from the moment when a developer finishes writing a feature to when it gets into production and end-users can use it.
It’s good to stay under 1 hour here. This implies one thing: automation.
You can’t have any manual approval process in place here with some QA specialists or managers standing in the way. The entire process needs to be automated. Quality and security checks should be handled by the developer while working on a feature.
This level of automation works to secure the product as well. The developer shouldn’t be able to ship something that uses a library with a known vulnerability. A well-configured and automated pipeline will push such a commit back to the developer, letting them know what needs to be fixed.
Lastly, it’s about cross-team independence again. The team needs to be capable of moving code into production without having to get in touch with other teams.
Conway’s law states the following:
“Any organization that designs a system will produce a design whose structure is a copy of the organization’s communication structure.”
In a way, if organizations don’t export their organizational charts, they tend not to have highly autonomous teams. Maybe it’s time for Conway’s inverse maneuver to draw a new organizational chart. For example, it’s a bad idea to have your engineering team depend on an external team to modify their CI/CD pipeline.
2. “If it hurts, do it more often” – Deploy several times a day
Ideally, releasing code to production should be a non-event at the company. If you release often, the batch will be smaller, safer, and less complex. And even if you’re still working on a feature, release it into production under Feature Flags.
Use the best practice of CanaryRelease too. It’s a technique that reduces the risk of introducing a new version into production by slowly rolling out changes to a small subset of users before making them available to everyone.
Antipatterns to watch out for:
- Change Advisory Board (CAB) – while lightweight change management is a good thing, a board is an external entity that gives you a sign-off. They have no idea what you’re up to – they have no context and can’t validate risks, so their feedback isn’t relevant. Nicole Forsgren and Jez Humble showed in their book Accelerate that CAB correlates with instability and slower speed. So it just doesn’t make sense to do it.
- Allowing deployment to production only outside of business hours – Many organizations say that they can’t release a new version during critical business hours and make changes to production. They only allow it out of business hours – late evenings/night/weekends. You can solve this by fixing technical issues so you can deploy code to production as soon as you finish working on features.
3. Mean Time To Recovery (MTTR)
Incidents will happen, so what matters is how quickly you can recover.
Here are a few helpful best practices:
- Automatic rollbacks – For example, if 30% of users start getting errors, it’s a sign system should roll back to the previous version that works fine.
- Your code is always deployable – You know that you have a code version that worked well and that you can always roll back to.
- Blameless postmortems – After an incident, hold a postmortem event to discover what really happened, what the cause was, and formulate learnings from it. Make sure the meetings are blameless – you need to maintain a sense of psychological safety. Make sure that the learnings are executed later on.
- Runbooks – When working at night on-call, engineers should have documented procedures covering what to do when things go bad. Runbooks reduce the stress level or demand for heroic saves. They allow engineers to go back to sleep sooner and maybe even be productive the next day.
- Observability tools (metrics, logs, tracing) – Teams should spend a lot of time on building observability tools to know what happens in the product and diagnose problems.
- Circuit breakers – You need to have a firm grasp over your architecture so when one component of the product experiences a problem, it doesn’t cause a ripple effect and brings your business down with it.
4. Failed deploys, impaired service or complete outage <15%
When deploys fail, do they lead to an outage? This number should be as low as possible.
First, shift the responsibility. If the people who built the product will also be the ones to support it, how the team works will change naturally. Especially if team members need to be on-call at night and fix things anytime. Nobody wants to get paged in the middle of the night. So often, engineers are more likely to go the extra mile when building quality into the product.
Nicole Forsgren and Jez Humble showed in Accelerate that there’s no tradeoff between velocity and stability; they actually go together nicely.
If the failure rate starts to increase, consider carrying out a stability sprint where you focus on operational excellence and address technical debt.
For example, Google product teams have error budgets. When they exhaust their internal service level objective, they shift from new feature development to technical debt and operational excellence.
Do these DevOps metrics really measure culture, time to market, and related things?
They do.
I already mentioned Nicole Forsgren and Jez Humble’s great book Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations.
It talks about this and brings up stories of many startups and tech giants who saw many good things happen after measuring these metrics.
At CAST AI, we implemented these metrics from day one
Here’s how we implemented it at CAST AI. We started with a comprehensive suite of unit, integration, and end-to-end tests. We’ve built all infrastructure environments with code.
Various checks in the CI pipeline for unfriendly OSS licenses, known vulnerabilities, linters, and other issues meant that many paper cuts are solved before raising pull requests. That way, the peer review process can focus on more important discussions rather than nitpicking.
Our rigorous peer review culture provided very lightweight change management in the form of pull requests/comments in GitLab. Having strong quality gates through the test suite and peer review removed the fear of automated deployments with GitOps (ArgoCD).
We started monitoring and on-call duty before we released the product to MVP. Not to fix things during the night, but to start a blameless postmortem process rolling, extract learning, and make technical debt visible, validate our observability tools efficiency and gaps.
During sprint planning, we reserve capacity for postmortem fixes, technical debt, and operational excellence. Of course, sometimes opportunities arise and you have to crunch through on features, but we’re like the Lannisters – we always pay our debts.
We have our quarterly targets:
- how fast we aim to respond to the page,
- how long it takes to fix (rollback or forward fix),
- deadlines to address the findings from postmortems.
We never stand still. Recurring retrospectives, dev-wars discussions on what to improve, how we code next and postmortems keep us on our toes to never stop improving and adapting to the changing landscape.
Time management tips and tricks for developers

When a distraction happens, it doesn’t only cost you the direct time of that distraction. It costs the additional 23 minutes 15 seconds that it takes developers to get back on track.
At least half of interruptions are self-induced.
People compensate for interruptions by working faster, but this comes at a price: more stress, higher frustration, and effort.
Research shows that sustained stress leads to poor risk management, the ability to analyze new information, shrinks brains, and causes burnout.
A poorly placed 30-min meeting can ruin half of a developer’s day.
Paul Graham wrote about this in Maker’s Schedule, Manager’s Schedule.
He explained how managers get into the way of developers and cause them to be less productive. For example, managers like to hold speculative meetings or have quick chats just to get to know people better. The trouble is, these meetings are very distracting.
So, here’s what you can do to maximize the efficiency (and happiness) of your engineering team:
- Have 1-2 days every week without any meetings at all to help developers to focus on their work,
- Clump meetings together without any short time windows between them (nothing productive can be done within 10-30 minutes anyway),
- Amazon-style memos work really well – at CAST AI, we circulate memos at the beginning of meetings and then get 5 mins to read them. This facilitates the discussion because everyone is on the same page.
Wrap up
Deliberate “quick & dirty” has its uses. But product development is a marathon.
Go for a sustainable model of working and never stop pushing these DevOps metrics numbers down. This is how you make sure that your team is healthy and motivated – and that it rocks at delivery.
Note: This article is based on a talk I gave at the Startup Lithuania, you can find the video here.



